漏洞分析技术
0x01 软件漏洞原理
传统的缓冲区溢出漏洞,UAF(Use-After-Free)等涉及二进制编码的漏洞统称为二进制漏洞。
1.1 缓冲区溢出漏洞
程序在运行前会预留一些内存空间,这些内存空间用于临时存储I/O数据。这种预留的内存空间被称为缓冲区。
缓冲区溢出是指计算机向缓冲区填充的数据超过了缓冲区本身的容量,导致合法的数据被覆盖。从安全变成的角度欻,理想情况下程序在执行复制,赋值等操作时,需要检查数据的长度,且不允许输入超过缓冲区长度的数据。但有时开发人员会假设数据长度总是与所分配的存储空间相匹配,并默认程序运行时传入的数据都是合法的,所以不一定会对数据的合法性进行检测,由此给缓冲区溢出埋下了隐患。
1.1.1 栈溢出原理
栈(stack)是一种基本的数据结构,由编译器自动分配,释放。从数据结构的层次理解,栈是一种先进后出的线性表,符合“先进后出”的原则。在程序中,栈中保存了函数需要的重要信息,并在函数执行完毕时被释放。程序可以借助栈将参数传递给子函数。栈也可以用于存放局部变量,函数返回地址。栈赋予子程序一个方便的空间来访问函数的局部数据,并传递函数执行后的返回信息。
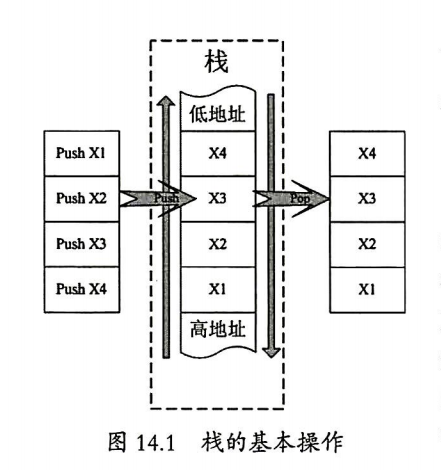
由于栈时向低地址方向生长的,而压入栈的变量是向高地址方向生长的,所以如果栈中的变量超过其最大分配缓冲区的大小是,就会覆盖前面被push到栈中的返回地址,导致函数在返回时发生错误,这就是栈溢出。
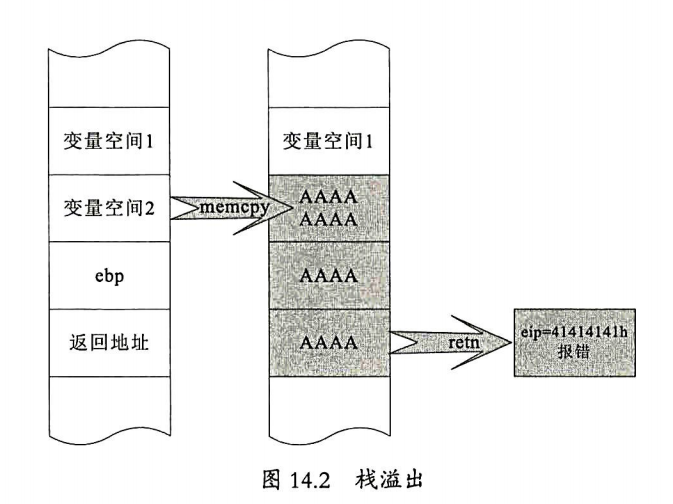
1.1.2 堆溢出原理
堆(heap)是一种基本的数据结构,它可由开发人员自行分配,释放。堆是向高地址扩展的,是不连续的内存区域。系统使用链表来管理空闲的内存块,链表的遍历是由低地址向高地址进行的。
堆溢出时给堆里面的变量赋予了超过了其分配的空间大小的值,堆链表的后续链表数据被覆盖所致。
1.2 整数溢出漏洞
在计算机中,整型是一个特定的变量类型。经过不同CPU架构的编译处理后,整型和指针所占字节数一般是相同的。因此再32位系统(如x86)中,一个整数占32位,64位系统,一个整数占64位。
一般开发人员再写程序时,对整型数仅考虑范围,不考虑安全要求。对不同用途的整型数,其安全要求也不相同。在32位系统中,无符号整数的范围时0~0xFFFFFFF,不仅要保证用户提交的数据在此范围内,还要保证对用户数据进行运算和存储后,其结果仍然在范围内。在实际应用中,开发人员可能会忽略这个问题,把它当作一个有符号整型使用。
整数溢出从成因的角度来说可以分3个大类分别是存储溢出,计算溢出和符号问题。
1.2.1 存储溢出
示例代码1:
int len1 = 0x10000;
short len2 = len1;
由于len1和len2的数据类型长度不一样,int 32位,short16位,len2无法容纳len1全部位,所以len2等于0。
示例代码2:
short len2 = 1;
int len1 = len2
以上结果len1并非总等于1,若初始值len1为0xFFFFFFF,结果len1就为0xFFFF0001
1.2.2 运算溢出
运算过程中造成整型数溢出时最常见的情况,其原理就是对整型数变量进行运算的过程中没有考虑其边界范围,造成运算后的数值超出了其存储空间,示例代码如下。
bool func(char *userdata, short datalength)
{
char *buff;
......
if(datalength != strlen(userdata))
return false;
datalength = datalength*2; //short类型运算超界使下面的拷贝发生溢出
buff = malloc(datalength);
strncpy(buff,userdata,datalength);
.....
}
1.2.3 符号问题
整型数分为有符号整型数和无符号整型数,因此符号问题也可能造成安全方面的隐患。在一般情况下,对长度变量都要求使用无符号整型数,如果开发人员忽略了符号,那么在进行安全检查的时候就可能出现问题。符号引起的溢出,最典型的例子就是eEye发现的Apache HTTP Server分块编码漏洞。
分块编码(chunked encoding)传输方式是HTTP1.1种定义的Web用户向服务器提交数据的一种方式,当服务器收到chunked编码方式的数据时会分配一个缓冲区来存放数据,如果提交的数据大小未知,那么客户端会以一个协商好的分块大小向服务器提交数据。
Apache服务器默认提供了对分块编码的支持。Apache使用了一个有符号变量来存储分块长度,同时分配了一个固定大小的栈缓冲区来存储分块数据。出于对安全的考虑,在将分块数据复制到缓冲区之前,Apache会对分块长度进行检查,如果分块长度大于缓冲区长度,Apache最多只复制缓冲区长度的数据,否则根据分块长度来复制数据。然而在进行上述检查时,没有将分块长度转为无符号型来比较,因此,如果攻击者将分块长度设置为负值,就会绕过上述安全检查,Apache会将一个超长(至少0x8000000字节)的分块数据复制到缓冲区,这会造成缓冲区溢出。
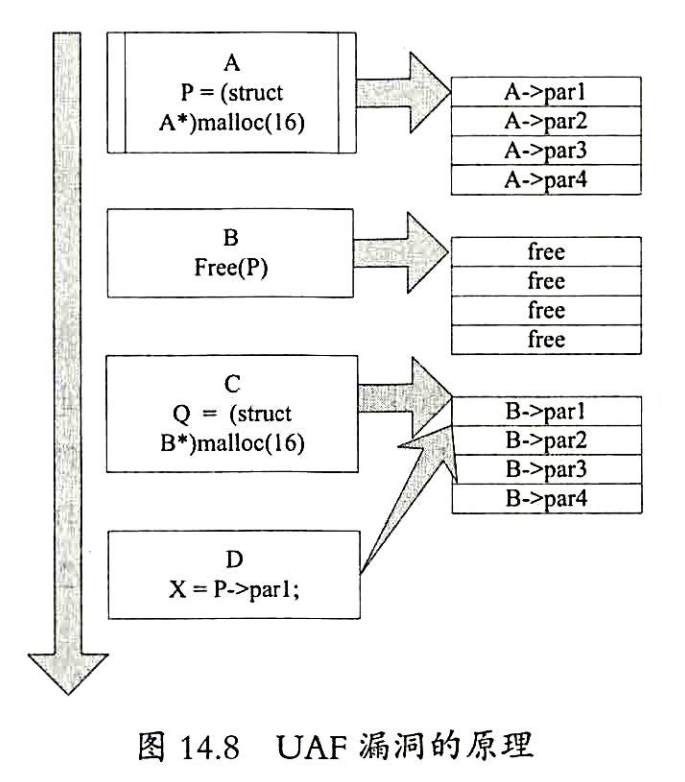
1.3 UAF漏洞
UAF(Use-After-Free)漏洞,其原理从字面意思就可以理解:释放后被重用。如图,A先后调用B,C,D这3个子函数;B会把A的某个资源释放;D判断不严谨,即使在B把A的资源释放后依然引用它(例如某个指针),这使D引用了危险的悬空指针。因此,利用方法是:构造“奇葩”的数据,让A调用B;B会把A的某个指针释放;执行C,C赶紧申请分配内存,企图占用刚才被释放的空间,同时控制这块内存,D被调用,由于检查不严格,调用了已经被释放的指针,实际上该指针对应的内存空间已经被C重用了,导致漏洞被利用。
0x02 Shellcode
Shellcode实际上是一段可以独立执行的代码(也可以认为是一段填充数据),再出发了缓冲区溢出后并获取了eip指针的控制权后,通常会将eip指针指向Shellcode以完成漏洞利用过程。从功能上看,Shellcode在整个漏洞利用过程种发挥的主要作用就是实现对计算机端的控制。
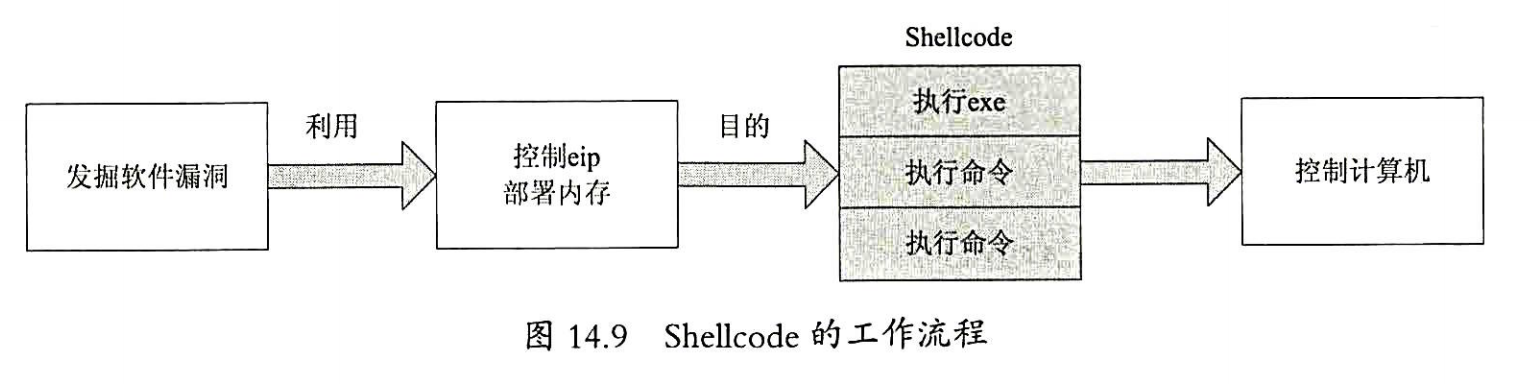
2.1 Shellcode的结构
Shellcode在漏洞样本中的存在形式一般为一段可以自主运行的汇编代码。它不依赖任何编译环境,也不能像在IDE中直接编写代码那样调用API函数名称来实现功能。它通过主动查找DLL基址并动态获取API地址的方式来实现API调用,然后根据实际功能调用相应的API函数完成自身的功能。Shellcode分为两个模块,分别是基本模块和功能模块。

2.1.1 基本模块
基本模块用于实现Shellcode初始运行,获取Kernel32基址及获取API地址的过程。
- 获取Kernel32基址
- 获取Kernel32基址的常见方法有暴力搜索,异常处理链表搜索和TEB搜索。在NT内核系统(32位)fs寄存器指向TEB结构,TEB+0x30指向PEB结构,PEB+0x0c指向PEB_LDR_DATA结构,PEB_LDR_DATA+0x1c偏移处存放着程序加载的动态链接库地址,第1个指向ntdll.dll,第2个是kernel32.dll的基地址,
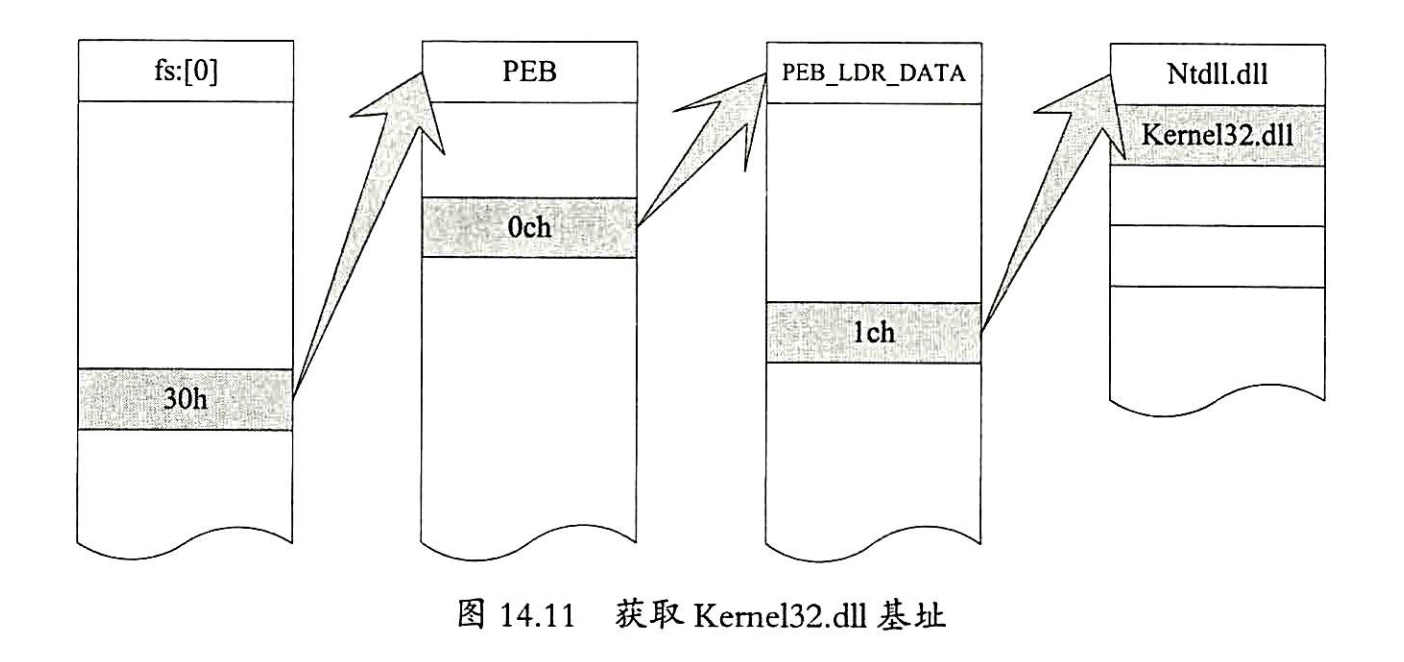
- 获取API地址
- dll基址+3ch找到e_lfanew的地址,即可获取PE文件头。在PE文件头78h偏移处得到函数导出表地址。在导出表1ch偏移处获取AddressOfFunction地址,在导出表20h偏移处获取AddressOfNames的地址,在导出表24h偏移处获取AddressOfNameOrdinalse的地址。也就是IAT,INT地址。
- 在实际应用中,如果API函数名称直接以铭文出现,就会降低Shellcode的分析难度。而且API函数名称占用的空间一般都比较大,这会使得Shellcode的提及增大。所以可以使用算法计算函数名hash,对比hash是否相同来减小shellcode的体积,同时增加shellcode的隐蔽性。通过kernel32.dll的LoadLibray和GetProcessAddress函数就可以获取任意DLL的任意函数的地址。
2.1.2 功能模块
功能模块就是实现漏洞利用部分的shellcode。基础模块所作的工作就是在这里实现相应的功能。下面介绍Shellcode的几种常见功能。
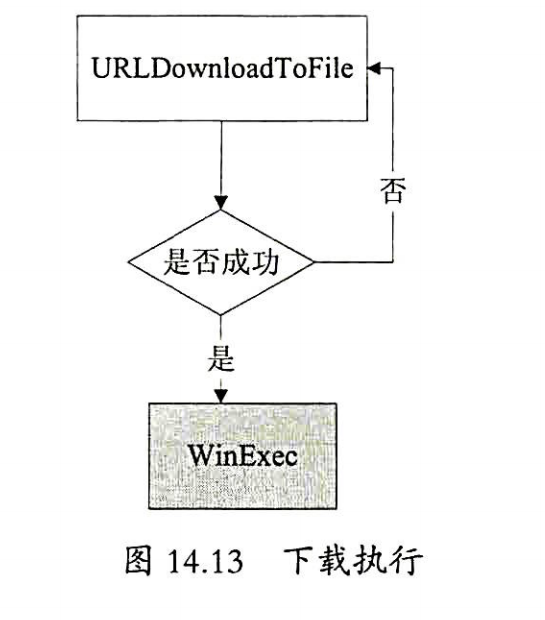
- 下载执行
- 具有这个功能的shellcode最常被浏览器类的漏洞样本使用,其功能是指定URL下载一个exe文件并执行。
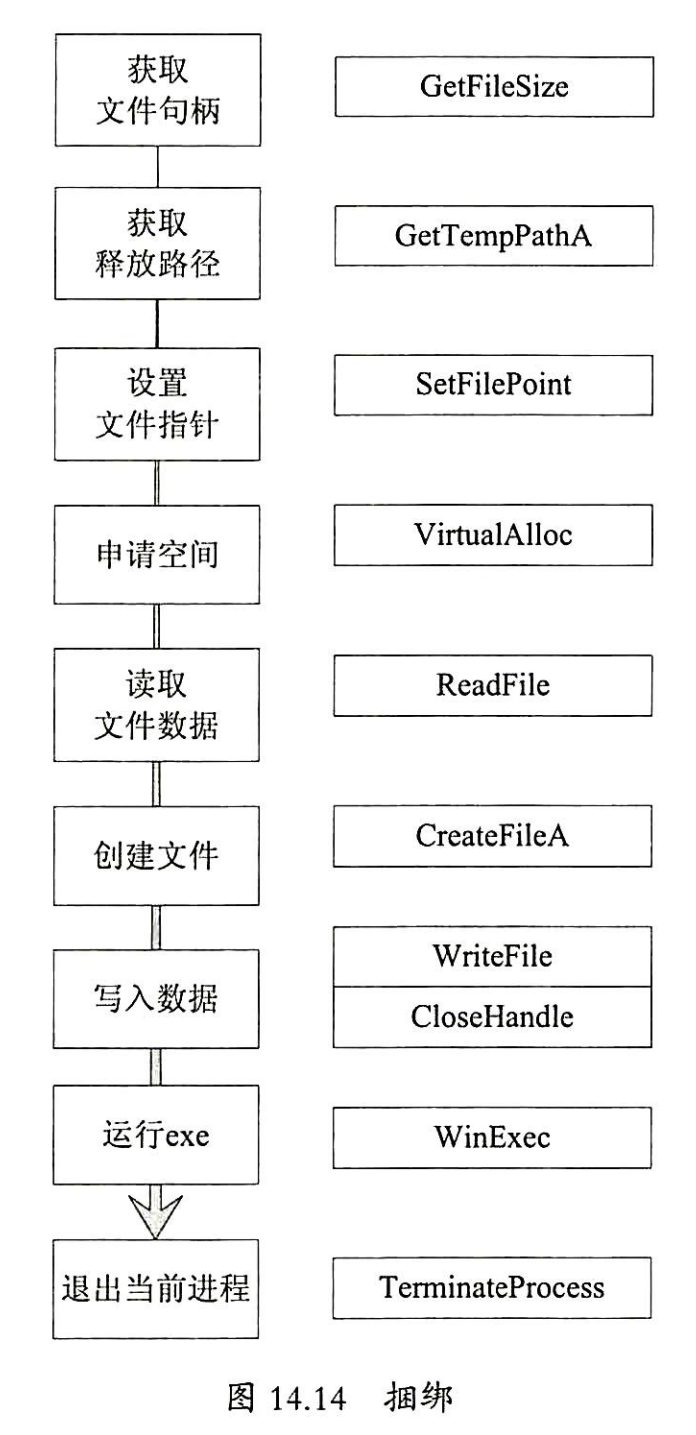
- 捆绑
- 具有这个功能的Shellcode最常见于Office等漏洞样本中,其功能是将捆绑在样本自身上的exe数据到指定目录中并运算。
- 反弹shell
- 具有这个功能的Shellcode多见于主动型远程溢出漏洞样本中,攻击者可以借助NC等工具,在实施攻击后获取一个远程Shell以执行任意命令,工作流程。
2.2 Shellcode通用技术
由于windows操作系统中API的延续性,其功能,参数等变化都很少,而Shellcode的通用技术集中在基本模块中,如何在不同的系统环境下动态找出DLL基址就成为我们所面临的问题。
从windows vista开始,程序中DLL基址的加载顺序发生了变化,在固定的位置已经不能得到正确的kernel32基址了,因此,需要在列表中对各DLL模块的名称加以判断,才能得到正确的kernel32基址。
2.2.1 代码的编写
查看之前0day书上的文章
2.2.2 shellcode的提取
提取shellcode的一般方法是:利用十六进制编辑器打开生成的shellcode.exe文件,找到shellcode对应的区段,将代码复制出来。
自动化提取的原理是:利用C++,读取内联汇编区域所对应的内存数据,并将存储为指定的数据格式。
2.2.3 shellcode的调试
因为shellcode是以内联汇编的形式写在代码中的,所以可以直接利用VC对其进行动态调试,也可以利用od加载exe程序来调试。如果是bin文件,需要自己写shellcodeloader。
2.2.4 shellcode的变形
在漏洞样本分析中,常见的shellcode可能不是能够直接进行反汇编的bin数据,而是经过了一些变形的数据。
- 格式变化
- 最常见的shellcode是以二进制格式存在的,但在不同的样本中,由于数据处理格式不同,也可能出现其他形式的shellcode。
- unescape格式:在浏览器样本中常见
- HexToAscii格式:在rtf漏洞样本中会遇到
- 其他语言格式:C++,Delphi,汇编语句等格式
- 字符串化
- 在原始的shellcode中难免会有非可见字符或者休止符(0x00)出现,这样在一些特定的样本中就容易造成终端,导致漏洞利用失败。因此,需要对shellcode进行字符串化的变形,如纯字母的shellcode等。
- 加密
- 加密是当前漏洞样本中的一种常见手段,用来实现免杀或者提高漏洞样本的分析难度。常见的加密方式有简单异或,非0字符异或,十六进制加减,base64编码等,一些加密处理甚至引入了高级加密算法。
0x03 漏洞利用
3.1 漏洞利用基本技术
漏洞利用的目的主要是通过控制eip来运行shellcode。首先我们来了解一下在漏洞利用过程中shellcode可能出现的位置。
3.1.1 jmp esp/call esp
对于保存在栈空间中的shellcode,一般通过填充jmp esp指令地址的方式来控制eip,使eip指向shellcode,原理如下图。
3.1.2 jmp ebx/call ebx
尽管jmp esp指令可以胜任一部分栈溢出漏洞的利用工作,但有一种栈溢出漏洞的利用方式不得不提,那就是借助jmp ebx指令。这两种方式相互补充,可以提高栈溢出漏洞利用的成功率。
在发生栈溢出后,如果覆盖的返回地址是一个无效地址,那么操作系统会进入异常处理过程,展现给用户的就是程序弹出一个错误对话框。
在windows操作系统中,当遇到一个无法处理的异常是,会查找异常处理链表,从中找到对应的异常处理程序。
当系统进入异常处理链表后,ebx中的指针指向当前下一个异常处理地址。将异常处理程序1的地址用jmp ebx指令地址覆盖,eip就会指向它前4字节的地方,再把这4填充“EB 04”,使eip指向shellcode。

3.1.3 堆喷射
堆喷射(Heap Spray)技术多见于UAF漏洞的利用中。因为再UAF漏洞中往往只能控制eip,shellcode无法写入指定的内存,所以,采用脚本循环申请的方式来填充连续的内存可以使shellcode被相对固定地写入某段内存区域,从而实现shellcode布局,最后通过控制eip来指向shellcode。
3.2 漏洞利用高级技术
3.2.1 什么是DEP保护
数据执行保护(Data Execution Prevetion,DEP)这一安全机制的设计初衷。
DEP是由微软提出的,从Windows XP开始支持该安全特性。DEP需要硬件页表机制的支持。因为再x86架构的页表没有NX(不可知行)位,只有x64系统才支持NX位,所以,WindowsXP的和Windows Sever2003再64位CPU中直接使用硬件的NX位实现,而在32位系统中则使用软件模拟的方式实现。
DEP将非代码段的页表属性设置成“不可执行”,一旦系统从这些地址空间进行取指令操作,系统就会报告“内存违规”异常,进而杀死“进程”。栈空间也被操作系统设置了“不可执行”属性,因此,注入栈中的shellcode就无法执行了。
在windows xp中,默认的DEP使未开启的。
3.2.2 绕过DEP的方法
ROP(Retrun-Oriented Programming)。在其他的可执行的位置找到符合要求的指令片段,让这部分指令代替shellcode完成准备工作。为了控制程序的流程,在指令片段的最后要有一条返回指令,以便收回程序的控制权,进行下一指令片段中的操作。
ROP是一种全新的攻击方式,主要借助代码复用技术来实现功能。攻击者查找已有的动态链接库和可执行文件,从中提取可以利用的指令片段(gadget)。这些片段均以ret/retn指令结尾,即使用ret/retn指令实现执行流的衔接。每个程序都会维护一段运行栈,栈为所有函数共享。每次进行函数调用时,系统会将一个栈帧分配给当前的被调用函数(用于参数的传递,局部变量的维护,函数返回地址的保存等)。ROP攻击会将前面得到的gadget地址和参数按照一定顺序放到运行栈中,以实现特定的执行流程。这些拼接起来的指令片段完成攻击者预设的目标操作。
ROP也有其不同于正常shellcode的内在特征,具体如下。
- 在ROP控制流中,ret指令不操纵函数,而将函数里面的段指令序列的执行流串起来。但在正常函数中,ret代表函数的结束。
- 在ROP控制流中,jmp指令在不同的库函数甚至不同的库中跳转,攻击者抽取的指令序列可能来自任意二进制文件的任意位置,这与正常程序的执行有很大的不同。例如从函数中部提取的jmp短指令序列可将控制流转向其他函数的内部,而当正常程序执行时,jmp指令通常在同意函数内部跳转。
基于ROP的特性,全靠ROP来完成shellcode的功能使非常困难的。ROP完成的操作通常是,通过调用VirtualProtect函数,将shellcode区域的内存设为“可执行”,或者通过VirtualAlloc函数申请一段可执行的空间,将shellcode复制过去,在跳至shellcode处执行。
3.2.3 ASLR保护及其绕过技术
ASLR是一种针对缓冲区溢出和ROP攻击的安全保护技术,通过对堆,栈,共享库映射等线性区布局的随机化处理,增加攻击者预测目标地址的难度,从而防止攻击者直接定位相关代码。
目前常见的绕过ASLR保护的方法是尝试查找未启用“Randomized Base Address”选项的程序。
0x04 漏洞样本
漏洞样本是软件中存在漏洞利用的最直接的证据,一般分为两类:一类是证明软件有漏洞,这类漏洞对那个不需要深入展示漏洞利用的过程,一般只需要证明样本可以导致程序崩溃(DoS),这类样本叫做PoC;另一类是漏洞利用样本,这类样本叫做Exp。
4.1 按样本格式分类
- 可执行文件
- *.exe,此类样本主要以本地提权,RPC,SMB,RDP等远程溢出为主,直接利用exe程序触发漏洞的执行,从而实现提权或远程溢出的目的。
- 文档类
- 此类样本本身没有执行的功能。当漏洞的应用程序打开此类样本的时候,会触发应用漏洞,实现执行shellcode的目的。
- 浏览器类:存在的一般为*.hmtl,*.htm等,主要用于触发浏览器漏洞,经常出现在IE,Firefox,Chrome等浏览器中
- 办公文档类:.pdf,.doc,.xls,.rtf等。主要用于触发Office系列应用程序的漏洞,常见于Adobe及Miscrosoft Word等应用程序中。
4.2 按用户群体分类
- 常见应用软件漏洞
- 包括Office类办公软件,浏览器类软件等。
- 专用软件
- 包括杀毒软件,Oracle软件等。
4.3 按作用范围分类
- 远程漏洞
- 不需要再被攻击计算机本地运行的漏洞样本,例如常见的RPC溢出漏洞。
- 本地漏洞
- 需要在被攻击计算机上运行的漏洞样本,例如本地提权类漏洞,办公软件漏洞。
0x05 样本分析
常见的漏洞分析过程是指对已知漏洞样本进行原理分析,从而找出漏洞成因及修补方案。我们在大多数情况下遇到的样本都是没有具体漏洞信息的,需要对样本进行静态分析,动态调试才能确定这些信息。准确地分析样本并编写样本检测规则是一个漏洞(病毒)分析者的基本技能。
5.1 准备工作
- 样本获取
- 样本获取的渠道有如下几个:
- 漏洞发布网站:很多漏洞样本都可以在exploit-db等站点找到。这些站点提供的漏洞类型也比较丰富,不仅有二进制漏洞,还有SQL注入漏洞,XSS漏洞等。
- 漏洞利用平台:例如Metasploit等漏洞测试和利用工具,可以用来提取分析样本。
- 交流平台:论坛,技术交流群等。
- 用户提交:这时杀毒软件厂商获取漏洞样本的一个重要途径。
- 环境搭建
- 搭建一个合适的漏洞分析环境是进行漏洞样本分析的重要前提,需要从以下几个方面考虑。
- 硬件平台:x86或x64平台,一般使用虚拟机来模拟。虚拟机不仅有很强的灵活性,而且可以保存快照,从而方便分析人员保存漏洞关键现场,以备随时还原,反复调试。
- 操作系统:根据样本的具体情况搭建,主流环境有Windows XP,Windows 7,Windows Server 2008和Windows 10等。
- 测试软件:Microsoft Office,Adobe Reader,IE,FireFox等,可根据样本实际情况安装对应版本的软件。
- 分析工具:包括动态分析工具和静态分析工具。
- 杀毒软件:杀毒软件在漏洞分析也能起到很好的辅助作用。例如,拿到一个样本后,可以先将其放在VirSCAN等测试平添进行查杀测试。因为各大杀毒软件公司的分析人员可能已分析过该样本,可以从平台上获取一些重要信息(如漏洞编号等)。
5.2 静态分析
参考实验
5.3 动态调试
参考实验
5.4 追根溯源
参考实验

文章评论