编译过程
0x00 前言
近期准备使用AFL进行Fuzz,但是在编译插桩过程中却编译失败了,所以打算从最基础的原理来找出错误,解决问题。
0x01 前置知识
1.1 GCC编译器
1.1.1 前端接口
前端将高级语言源码经过词法分析,语法分析生成与高级语言无关的低级中间表示GENERIC,然后经过单一赋值转化为另一种中间表示层GIMPLE,在中间层GIMPLE组件控制流程图,并在GIMPLE上进行一系列优化。然后将其转化成更加便于优化的RTL中间表示层。此时已经与高级语言无关了。
1.1.2 中间接口
中间接口主要在RTL中间表示上进行各种优化,GCC的优化技巧根据版本不同而又很大的不同,但都包含了标准的优化算法,如循环优化,公共子表达式删除,指令重排序等。(感觉后续需要去看一下相关的源码,便于逆向优化代码时候的源码还原)
1.2.3 后端接口
GCC后端对每条RTL通过模板匹配的方法调用对应的汇编模板生成汇编代码,生成的代码因处理器和结构不同而不同(汇编指令同样依赖于cpu架构,本质上就是机器码的别名),GCC后端为不同的平台提供了描述指令的汇编模板文件。这个阶段非常复杂,因为必须考虑GCC可移植平台的规格与技术细节,解决指令选择和寄存器分配等问题。
1.2.4 GCC常用的参数
- -c:只编译,不链接成为可执行文件。(该选项可以用于加快编译过程,只编译修改了的文件然后重新链接,子程序一般生成的目标文件不可单独执行)
- -o:output_filename。不给就默认生成a.out
- -g:产生符号调试工具
- -O*:对程序进行优化编译,链接。数字越大效果越好,编译,链接越慢
- -v:GCC执行时执行的详细过程,编译程序时可以查看搜索头文件,库文件的搜索路径
1.2 编译器LLVM
LLVM是构架编译器的框架系统,由C++编写而成,用于优化以任意程序语言编写的程序的编译时间,连接时间,运行时间以及空闲时间。
0x02 GCC
2.1 GCC的系统架构
GCC是一种管道架构(pipeline),通过不同层次为不同的数据类型进行通信。前端编译器针对特定语言进行词法和语法分析,解析为树状结构和中间表示代码(使用寄存器传递语言,Register Transfer Language,RTL)。后端编译器提供与具体语言无关的分析优化和针对特定目标架构的代码生成,这样的架构利于使用RTL创建更快速或更简洁的代码,最优化的代码被代码生成器获取,然后生成目标代码。
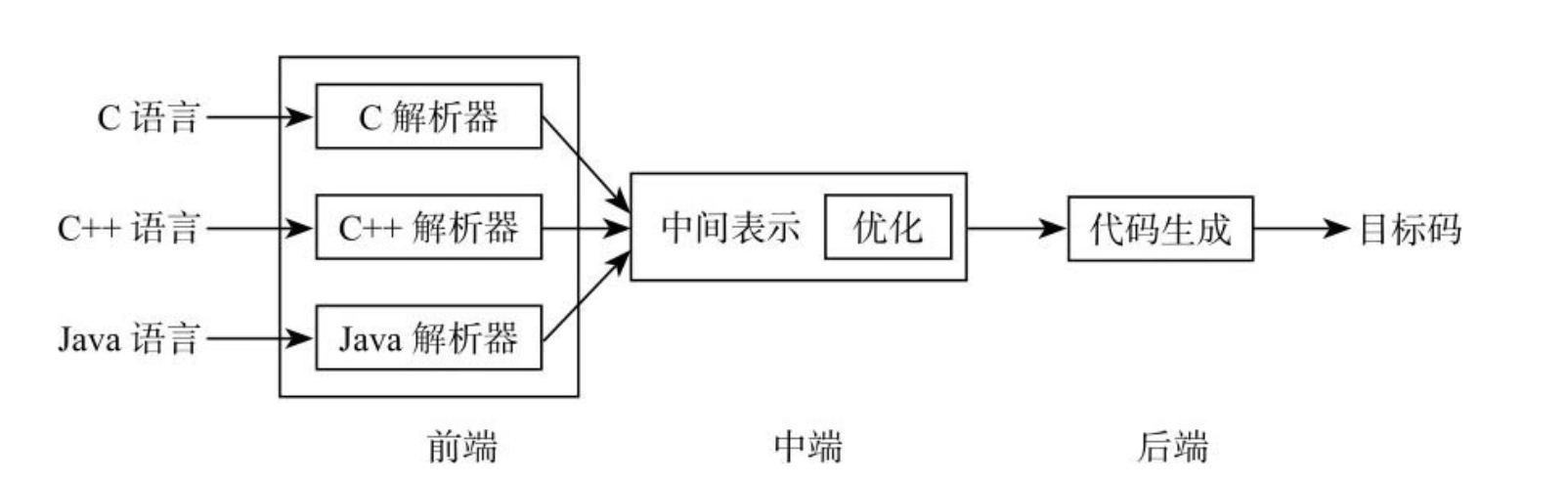
GCC的外部接口类似一个标准的命令行编译器。使用者在命令行下输入gcc命令,以及一些命令参数,以便决定每个输入文件使用的个别编译选项,输出目标平台的目标代码,并选择性的执行链接器以生成可执行程序。
2.1.1 前端接口
GCC前端的功能在于产生一棵可让中后端处理的语法树。语法解析器是一个递归调用的函数。
2.1.2 中端接口
现代编译器通常把与源程序和平台无关的部分放在编译器中端,目的是在中间表示上进行更多的优化。常用的优化技术包括死代码清除,删除无用赋值,常量传播等。
2.1.3 后端接口
GCC后端因不同的处理器宏和特定架构的功能不同,后端接口的前半部分利用架构信息决定RTL的生成形式,因此虽然GCC的RTL在理论上不受到处理器影响,但是此阶段的抽象指令已经转换成目标架构的格式。
后端的最后步骤相当公式化,仅仅将前一阶段得到的汇编语言代码转换其寄存器与内存位置成相对应的机器码。
2.2 GCC的分析程序
在前端,主要包含词法分析和语法分析两方面的工作,GCC包含了几千行YACC代码。语法分析负责构造出程序的语法分析树。
对前端和高级的分析及优化而言,树是其核心的数据结构。经过语法分析的源程序都表示为树的形式。GCC实际上由三种树:GENERIC,GIMPLE和SSA。

2.3 GCC的中间语言及生成
在树结构优化完成后,开始RTL的生成与优化。RTL是一种低级的中间表示,包含5种对象类型:表达式,整型,宽整型,串和向量。
2.4 GCC的优化
GCC提供了O0,O1,O2,O3以及Os这几种不同的优化级别供用户选择,在这些选项中包含了大部分有效的编译优化选项,并且在这个基础上对某些选项进行屏蔽或添加,从而大大降低使用的难度。
书中记录了很多选项开启的优化选项,暂时不需要学习这方面的内容,优化前后代码的汇编对比对笔者更为重要,故而暂时放弃。
2.5 GCC的目标代码生成
GCC专门有一个阶段将RTL转换为ASM,代码生成的依据是机器描述。
针对每个平台,GCC有对应的Machine Description用于指导指令生成。代码存放于“gcc/config/<平台名称>”的目录下。
0x03 LLVM
3.1 起源
LLVM是底层虚拟机的英文缩写。
根据不同的场景,LLVM可能指示以下内容:
- LLVM项目/基础架构。此时,LLVM指代多个构建一个完整编译的项目,包括前端后端,优化器,汇编器,链接器,libc++。compiler-rt以及JIT引擎。
- 基于LLVM的编译器。此时LLVM指代部分或者完全采用LLVM基础架构构建的编译器。例如某个编译器可以采用LLVM作为前端或者后端,但是使用GCC以及GNU系统库函数进行最后的链接。
- LLVM库,此时,LLVM指代LLVM基础架构种可复用的代码部分。
- LLVM内核。此时LLVM指代在中间表示级别上所进行的优化以及后端算法。
- LLVM中间表示(LLVM IR)。此时,LLVM指代LLVM编译器的中间表示。
3.2 相关项目
3.2.1 LLVM内核(LLVM Core)
LLVM内核库文件提供了一个与源语言以及目标架构无关的现代优化器,同时为很多主流CPU提供代码生成。这些库基于LLVM IR进行构建,这些库文件大大简化了为新型编程语言设计编译器或者将其移植到现有编译器的难度。
3.2.2 Clang
Clang是一个支持C,Objective-C,C++和Objective-C++语言的开源编译器。在LLVM项目的开展过程种,其设计上的最重大的决策是将后端与前端分离开来作为两个单的项目,也就是LLVM内核和Clang。LLVM成为围绕LLVM中间表示(LLVM IR)的一组工具及,并依赖改进的GCC将高级语言代码转化为存储在Bitcode文件中的特定中间表示。Bitcode文件桶Java中的ByteCode文件类似。Clang作为LLVM项目组第一个专门设计的前端的出现。
3.2.3 Clang extra tools
Clang extra tools是一组基于Clang构建的工具,该工具体能够读取C或者C++代码进行重构以及代码分析。工具集中的主要工具包括:Clang Modernizer,Clang Tidy,Modularize以及PPTrace等。
3.2.4 Compiler-RT
Compiler-RT项目对目标架构提供硬件不支持的部分底层功能。例如,32位的目标架构通常缺少支持64位目标架构的指令。Compiler-RT通过与目标架构相关的优化函数在使用32位指令的情况下能够实现对64位架构的支持。
3.2.5 DragonEgg
DragonEgg将LLVM优化器以及代码生成器同GCC解析器进行集成,使得LLVM能够编译Ada,Fortran以及其他GCC编译器前端所支持的语言,并能够获得Clang所不支持的C语言特性。
3.2.6 LLDB
LLDB项目基于LLVM和Clang的库文件构建了一个功能强大的原生调试器。LLDB使用Clang的AST以及表达式解析器,LLVM JIT,LLVM反汇编器等工具提供了天衣无缝的使用体验。其执行速度快,同GDB相比具有更高的内存使用效率。
3.2.7 libc++与libc++ ABI
libc++与libc++ ABI项目为C++标准库提供了标准规划以及高效实现,包括对C++编程语言标准C++ 11的全部支持。
3.2.8 Vmkit
Vmkit项目旨在基于LLVM技术实现Java以及.Net虚拟机
3.2.9 Klee
Klee项目实现了一个符号虚拟机,该虚拟机适用定理证明器尝试遍历代码中的所有动态执行路径,进而找到代码中的缺陷或者证明代码的安全特性。Klee的主要特点是能够在检测到代码缺陷时自动生成测试用例。
3.2.10 Poly
Poly项目实现了一组本地缓存的优化,以及使用polyhedral模型的自动并行化以及向量化。
3.2.11 lld
lld项目旨在实现Clang/LLVM的内建链接器。目前,Clang必须调用系统链接器才能够生成可执行代码。
3.3 LLVM前端
Clang是LLVM项目的原生编译器,支持C,Objective-C,C++和Objective-C++语言。同LLVM的名称类似,在不同的情况下,Clang具有不同含义:
- 前端(以Clang库文件形式实现)
- 编译器驱动(以Clang命令行以及Clang驱动库文件形式实现)
- 编译器(以Clang -ccl命令实现)。但是在clang -ccl命令执行过程中所涉及的编译器并不仅仅只涉及Clang库文件,该命令的执行广泛
在通常情况下,Clang多指代Clang库文件,即LLVM项目中类C语言的前端。为了将源代码转换为LLVM IR的bitcode,源代码需要经过一系列中间步骤。

3.3.1 前端库文件
Clang采用了模块化设计,通过若干个库文件予以实现,而不仅仅是作为驱动程序或者编译程序。其中libclang是同Clang用户交互的最重要接口,通过C语言实现前端功能。libclang中包含若干个Clang库文件,每个库文件可以单独链接也可以组合链接。
3.4 LLVM后端
LLVM后端即代码生成器负责将LLVM IR变换特定目标架构的机器代码,一方面,后端任务就是为某一目标架构生成最有的机器代码。
3.4.1 后端库文件
3.5 应用实例
3.5.1 代码插桩
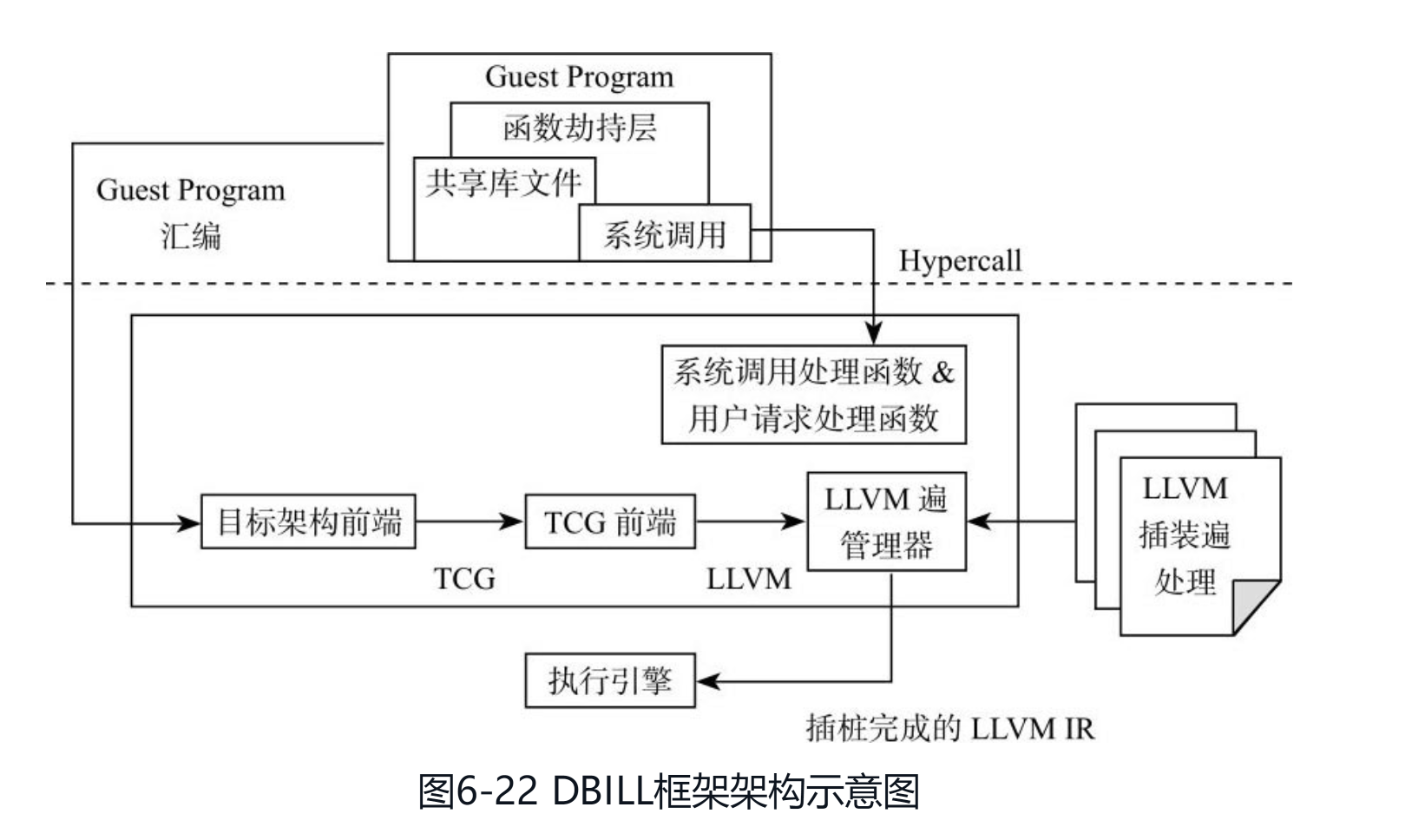
动态代码插桩是程序分析调试工具的核心技术之一。当前大部分动态插桩工具关注于相同指令集架构的插桩,即宿主代码与插桩代码采用相同的指令集编写。单是不同指令集架构下的插桩却不常见,如将ARM可执行代码插入x86架构下运行的代码。
DBILL是一种跨指令集架构的动态插桩框架,在框架的构建过程中用到了可重定向的动态二进制翻译工具QEMU。图6-22是DBILL的架构。DBILL框架的输入是一段二进制代码 (包括可执行程序、共享库文件或者动态链接库等)。如图中左边路径所示,QEMU的目标架构前端将该输入的二进制代码转换为TCG (Tiny Code Generator)表示,然后TCG前端将TCG表示转换为LLVM IR表示形式。LLVM遍管理器在LLVM IR中插入分析代码,然后由即时翻译器在运行时生成与插桩完成的LLVMIR相对应的对象代码
3.5.2 代码保护
Obfuscator-LLVM(ollvm)是在LLVM优化器中实现的一组代码混淆变换,旨在提高代码抵抗逆向分析以及篡改的能力。当前ollvm已经实现了指令替换,虚假控制流插入,基本快分割,控制流扁平化,过程合并以及抗篡改机制插入等内容,在其开发计划中还包括常量加密,垃圾代码插入以及抗调试代码插入。
在LLVM编译套件中,优化器主要负责无效代码或者冗余代码溢出,函数内敛,循环展开,死循环删除,控制流图简化工作。由于ollvm实现为优化器中的遍(Pass)处理,因此混淆以及抗篡改机制主要在LLVM的优化器中实现。这种方式无需指导代码的编程语言以及目标架构。该方式无法实现所有的保护技术,如抗调试代码的插入应该在代码生成阶段,即LLVM后端完成,而目前的ollvm所完成的操作主要在优化器中进行。
0xFF 尾注
由于本篇文章的主要目的是为了解决我进行FUZZ的编译问题,后来我查看提示是有两个变量未定义值但是使用了,手动初始化就编译成功了,暂时不进行这段内容的更新了。内容主要来自于《编译与反编译技术实战》这本书,书中的内容我看还有很多有意思的,后续在学习。

文章评论