IDA使用
缘由
最近几天发现IDA远程动态调试又又又出问题了,顺便感觉自己对工具使用仍然不太熟悉,决定看看《IDA pro权威指南》和IDA官方文档,记录一下IDA的功能。
IDA版本
7.7版本
反汇编器
反汇编的难点
- 编译过成会造成损失。
- 机器语言中没有变量或变量名,变量类型信息只有个通过数据的用途来确定。看到一个32位数据被传送,需要进行一番分析,才能确定这个32位数据表示的到底是一个整数,一个32位浮点数,还是一个32位指针。
- 编译属于多对多的操作。
- 源程序可以通过许多种不同的方式转换成汇编语言。机器语言也可以通过多种不同的方式转换成高级语言。编译一个文件,并立即反汇编,可能会得到截然不同的源文件。
- 反编译器非常依赖语言和库。
- 用用来生成C语言代码的反汇编器处理由Delphi编译器生成的二进制文件,可能会得到非常奇怪的结果。用对windows变成api一无所知的反编译器处理编译后的windows二进制文件,也不会得到任何有用的结果。
- 反汇编阶段的任何错误都会影响反汇编代码
反汇编的用途
- 分析恶意软件
- 分析闭源软件的漏洞
- 分析闭源软件的互操作性
- 分析编译器生成的代码,验证编译器的性能和准确性
- 在调试时显示程序指令
对我来说1,2,5功能是我所需要的。
分析恶意软件
由于缺乏源代码,动态分析和静态分析时分析恶意软件的两种主要技术。动态分析是指在严格控制的环境中执行恶意软件,并用系统检测实用工具记录其所有行为。相反,静态分析则试图通过浏览程序代码来理解程序的行为。此时,要查看的就是对恶意软件进行反汇编后得到的代码清单。
漏洞分析
安全审核过程划分成3个步骤:发现漏洞,分析漏洞,开发破解程序。发现漏洞,是发现程序中潜在的可供利用的条件。一般情况下我们可以通过模糊测试等动态技术来达到这一目的,也可通过静态分析来实现(通常代价会更高)。一旦发现漏洞,通常需要对其进行深入分析,以确定该漏洞是否可被利用,如果可利用,在什么情况下利用。
程序员声明一个70字节的数据,在由编译器分配时,会扩大到80字节。另外要了解编译器到底如何对全局生命或在函数中声明的所有变量进行排序,查看反汇编代码清单是唯一的办法。
软件互操作性
如果仅以二进制形式发布一个软件,竞争对手要想创建可以和它互操作的软件,或者为该软件提供插件,将会非常困难。如果我们想要达到这个目的,有可能需要完成大量逆向工程工作。
显示调试信息
在调试器中生成代码清单,可能是反汇编器最常见的一种用途。遗憾的是,调试其中内嵌反汇编器往往相当简单(OD是例外)
分类工具
file
file通过文件中的某些特定字段来确认文件的类型。某些文件类型特有的标签值(同通常成为幻数)如jpg文件的FF D8,PE文件的4D 5A(MZ),java .class file的CA FE BA BE。
二进制文件的符号
编译过程会在二进制目标文件中留下符号。在创建最终的可执行文件或二进制文件时,其中一些符号用于在连接过程中解析文件之间的引用关系。其他情况下,符号用于提供与所是使用的调试器有关的其他信息。
PE Tools
PE Tools时一组用于分析windows系统中正在运行的进程和可执行文件的工具。在其进程列表中,用户可以将一个进程的内存映射转储到某个文件中,也可以用PE Sniffer实用工具确认可执行文件由何种编译器构建,或者该文件是否经过某种已知的模糊实用工具 哈看PE文件头字段,使用该工具还可以方便的修改任何文件头的值。
二进制文件模糊技术
模糊指任何掩盖真实意图的行为。应用于可执行文件时,模糊是指掩盖程序真是行为的行为。该行为可以保护专有算法及掩盖恶意意图。
摘要工具
nm
将源文件编译成目标文件时,编译器必须嵌入一些全局(外部)符号的位置信息,以便链接器在组合目标文件以创建可执行文件时,能够解析对这些符号的引用。nm工具可以列举目标文件的符号。
使用nm检查中间文件(.o后缀),默认输出结果是在这个文件中声明的任何函数和全局变量的名称。如下:
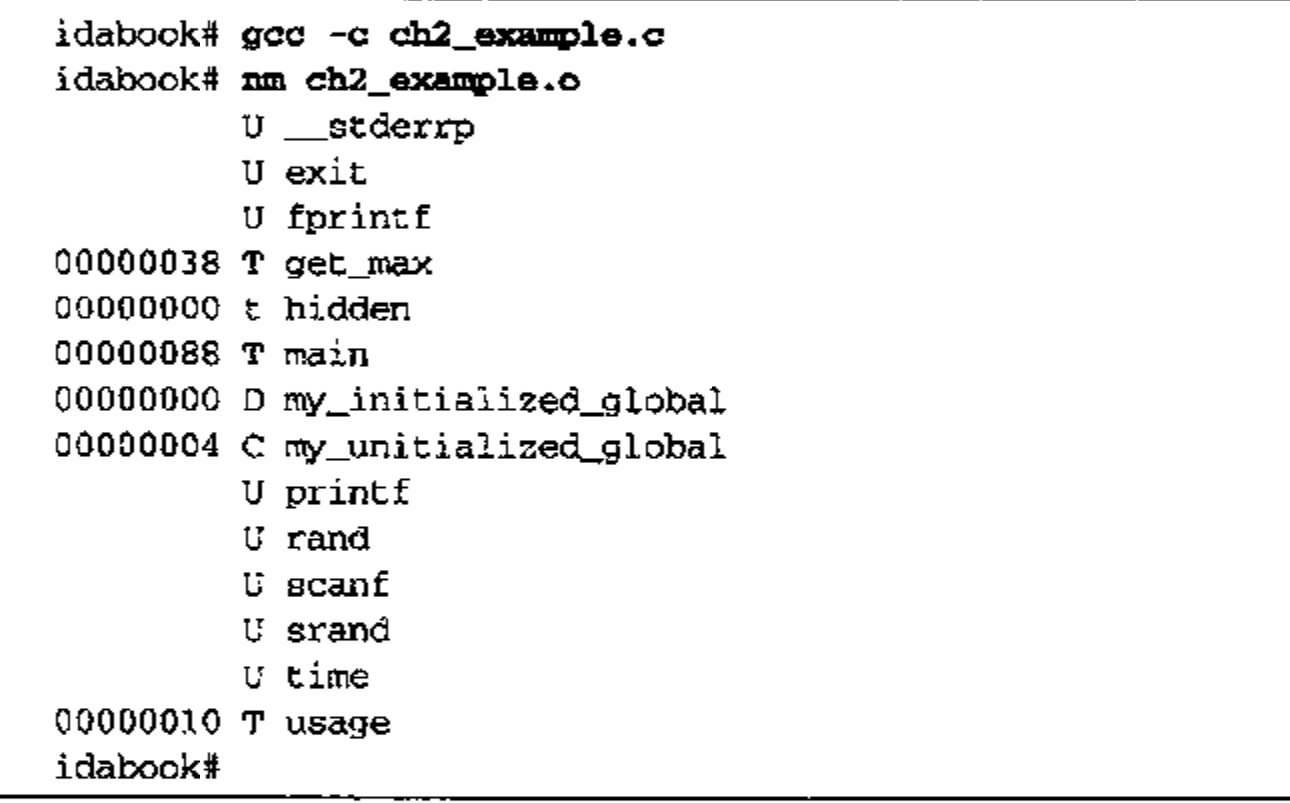
- U:未定义符号,通常为外部符号的引用
- T:在文本部分定义的符号,通常为函数名称
- t:在文本部分定义的符号。在C程序中,这个符号通常等于一个景天函数
- D:已初始化的数据值
- C:未初始化的数据值
在连接过程中,符号被解析成虚拟地址(如果有可能)
ldd
创建可执行文件时,必须解析他该文件引用的任何库函数的地址。连接器通过两种方法解析对库函数的调用:静态链接和动态链接。
静态链接,连接器会将程序的目标文件和所需的库函数组合起来,生成一个可执行文件。这样,在运行时就不需要确定库代码的位置,因为以及包含在可执行文件中了。在分析一个静态链接二进制文件时,要回答”这个二进制文件连接了那些库“。
动态链接,链接不需要复制它所需要的任何库。相反,连接器只需对所需库(.so,.dl)的引用插入到最终的可执行文件中。因此,这时生成的可执行文件也更小一些。
ldd(list dynamic dependencies)可以用来列举任何可执行文件所需的文件库。windows系统中,vs的dumpbin也可以列举某文件的依赖库dumpbin /dependents
objdump
objdump的功能是显示与目标文件有关的信息。
- 节头部
- 程序文件每节的摘要信息
- 专用头部
- 程序内存分布信息,还有运行时加载器所需的其他信息,包括ldd等工具生成的库列表
- 调试信息
- 提取出程序文件中的任何调试信息
- 反汇编代码清单
- objdump对文件中标记为代码的部分执行线性扫描反汇编。反汇编x86代码时,objdump可以生成AT&T或Intel语法,并可以将反汇编代码保存在文本文件中,这样的文本叫做反汇编代码清单。
c++flit
由于每一个重载函数都使用与原函数相同的名称,因此,支持函数重载的语言必须拥有一种机制,以区分同一个函数的许多重载版本。这种过程被叫做名称改编(name mangling)
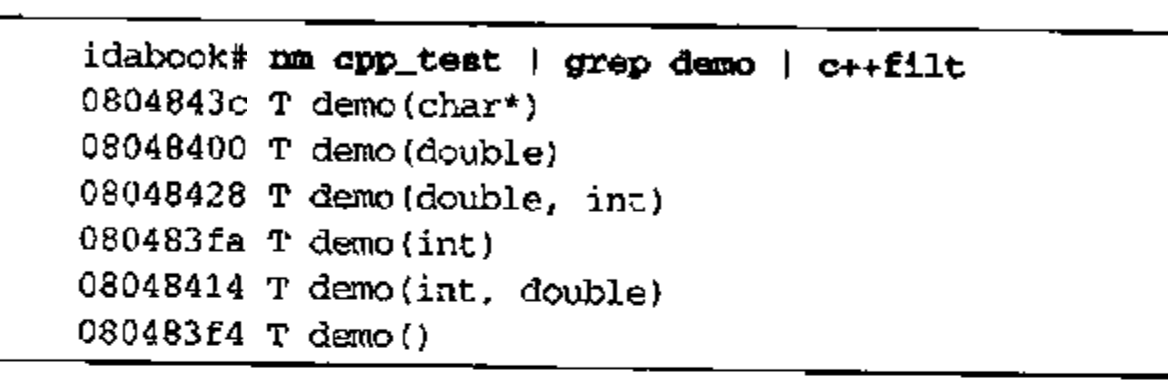
这一点应该在c++反汇编那本书种会再次提及。
深度检测工具
strings
默认情况下strings仅仅扫描文件中加载的,经初始化的部分。使用命令行参数-a可迫使strings扫描整个文件。
strings不会指出字符串在文件中的位置。使用命令行参数-t可以指出每一个字符串的文件偏移量
使用命令行参数-e可使strings搜索更广泛的字符,如16位unicode字符。
反汇编器
当遇到不采用常用文件格式的二进制文件,在这种情况下,需要一些能够从用户指定的偏移量开始反汇编的工具。
两个用于x86指令集的流式反汇编器:ndsiasm,diStorm。这些可以分析网络数据包中可能包含shellcode的部分。
IDA
IDB
IDA的任务时将选定的可执行文件加载到内存中,并对相关的部分进行分析。随后,IDA会创建一个数据库,其组件分别保存在4给文件中,这些文件的名称与可执行文件相同。.id0时一个二叉树形式的数据库,.id1文件包含描述每个程序字节的标记。.name问价内包含与IDA的Named窗口中显示的给定程序位置有关的索引信息。.til文件用于存储与一个给定数据库的本地类型定义有关的信息。
关闭项目后,这四个文件可以选择被压缩成一个IDB文件,如果工作目录存在这些,往往是因为数据库异常关闭。
加载器开始分析文件后,用户可能需要输入额外的信息,以外城加载过程。例如,使用PDB调试信息创建的PE文件。如果IDA发现一个程序数据库(program database,PDB)文件,他会提示你处理相应的PDB文件。
一旦IDA为某个可执行程序创建数据库,就不需要再访问这个可执行文件。
IDA数据显示窗口
反汇编窗口 IDA-View
列表视图:
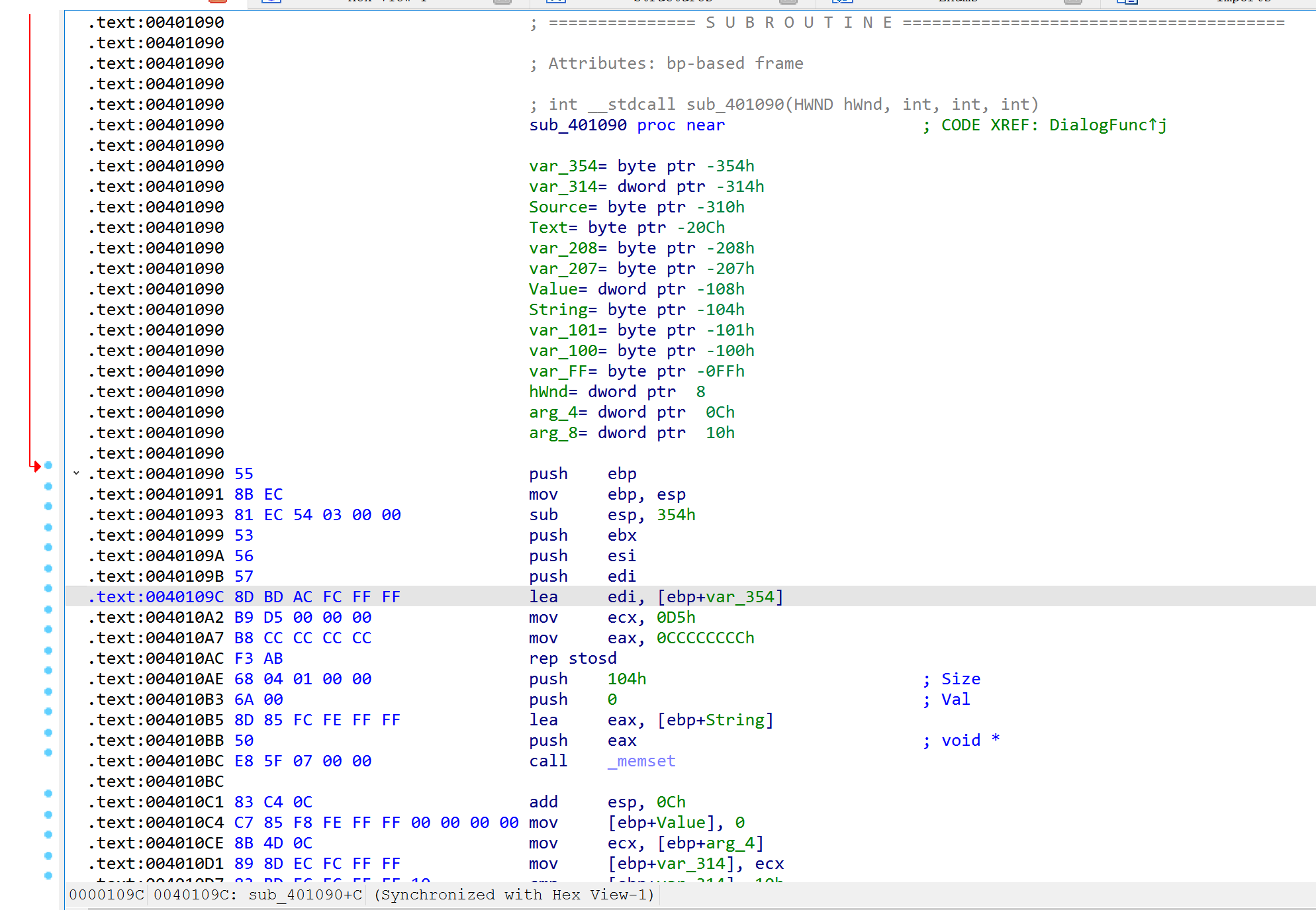
文本显示串口会呈现一个程序完整反汇编代码清单。用户只有通过这个窗口才能查看一个二进制文件的数据部分。

显示窗口左边的叫做箭头窗口,实现表示非条件跳转,虚线表示条件跳转。
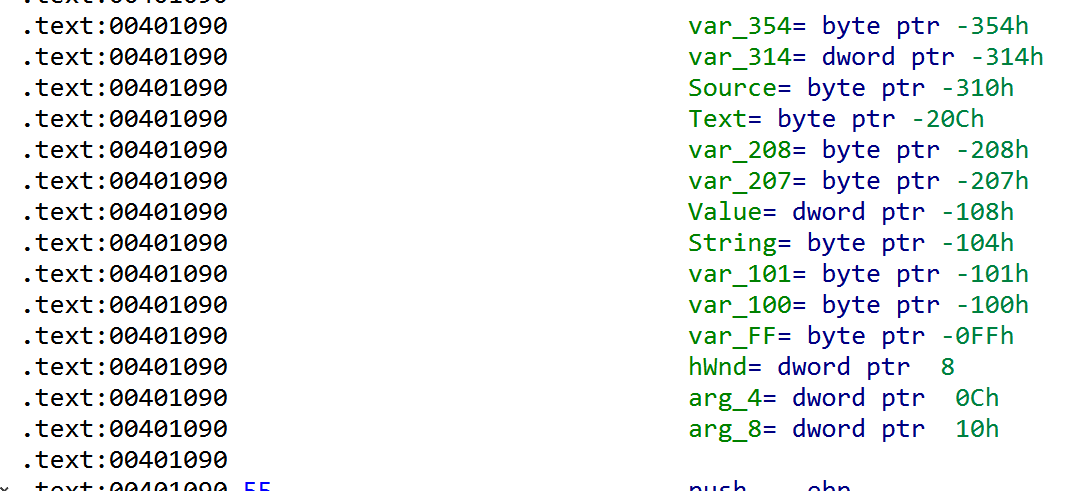
这是IDA对于函数栈帧布局的最准确估算。IDA对于函数栈指针及函数使用的任何栈帧指针的行为进行仔细分析,从而计算出该函数的栈帧的结构。

这里的代码交叉引用,它表示另一个程序指令引用了交叉引用注释所在位置的指令。
图形视图:
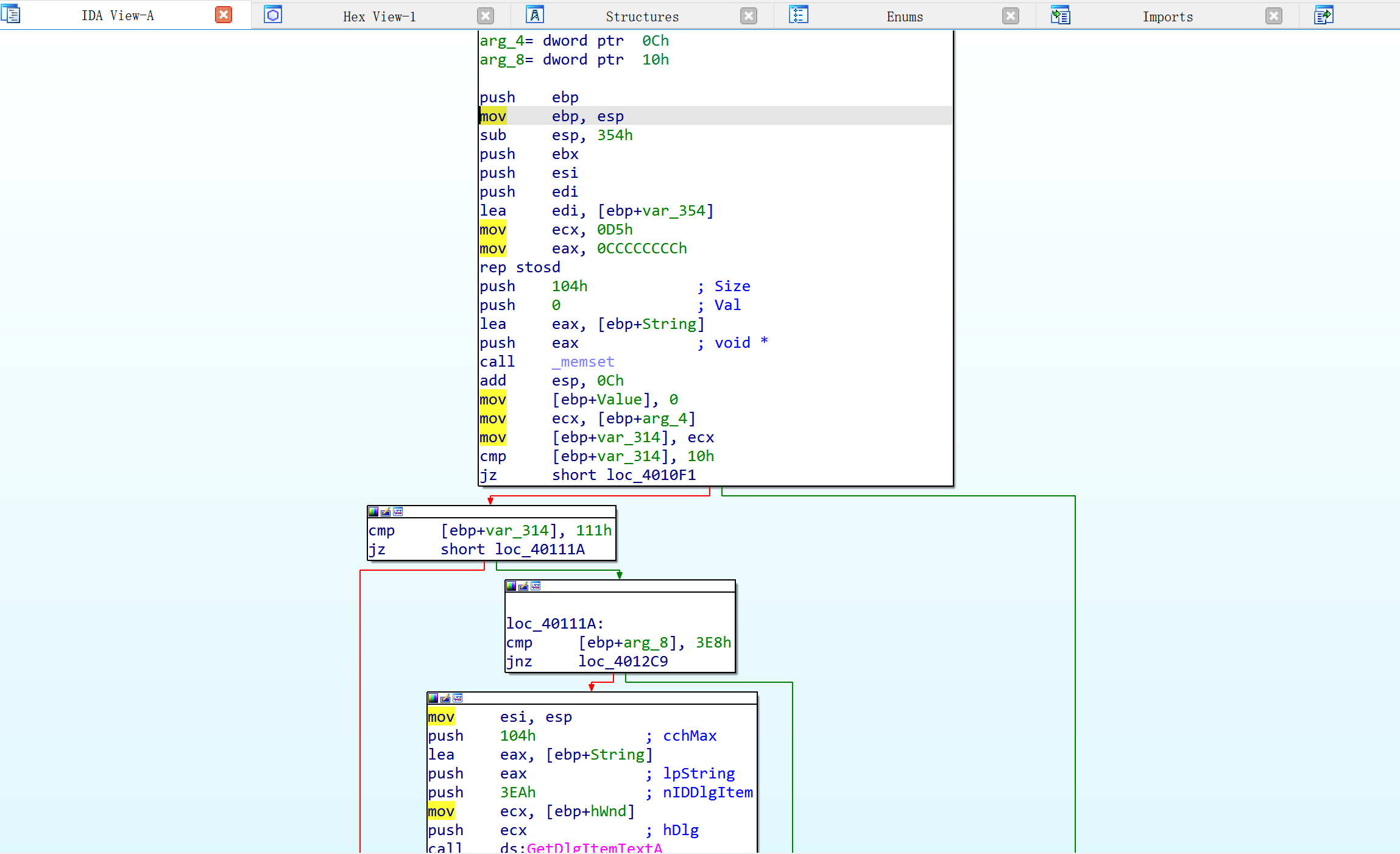
空格切换,图形视图将一个函数分解成许多块,根据条件跳转位置种植的基本快可能会生成两种流,YES的箭头为绿色,No的箭头为红色。
如果函数复杂可以看右下角的图形概况(graph overview)
右键某一个块,graph node可以折叠该块。
通过view - > oepnsubview - > disassembly命令打开另一个反汇编窗口。第一个叫IDA-ViewA,后续叫IDA-ViewB。
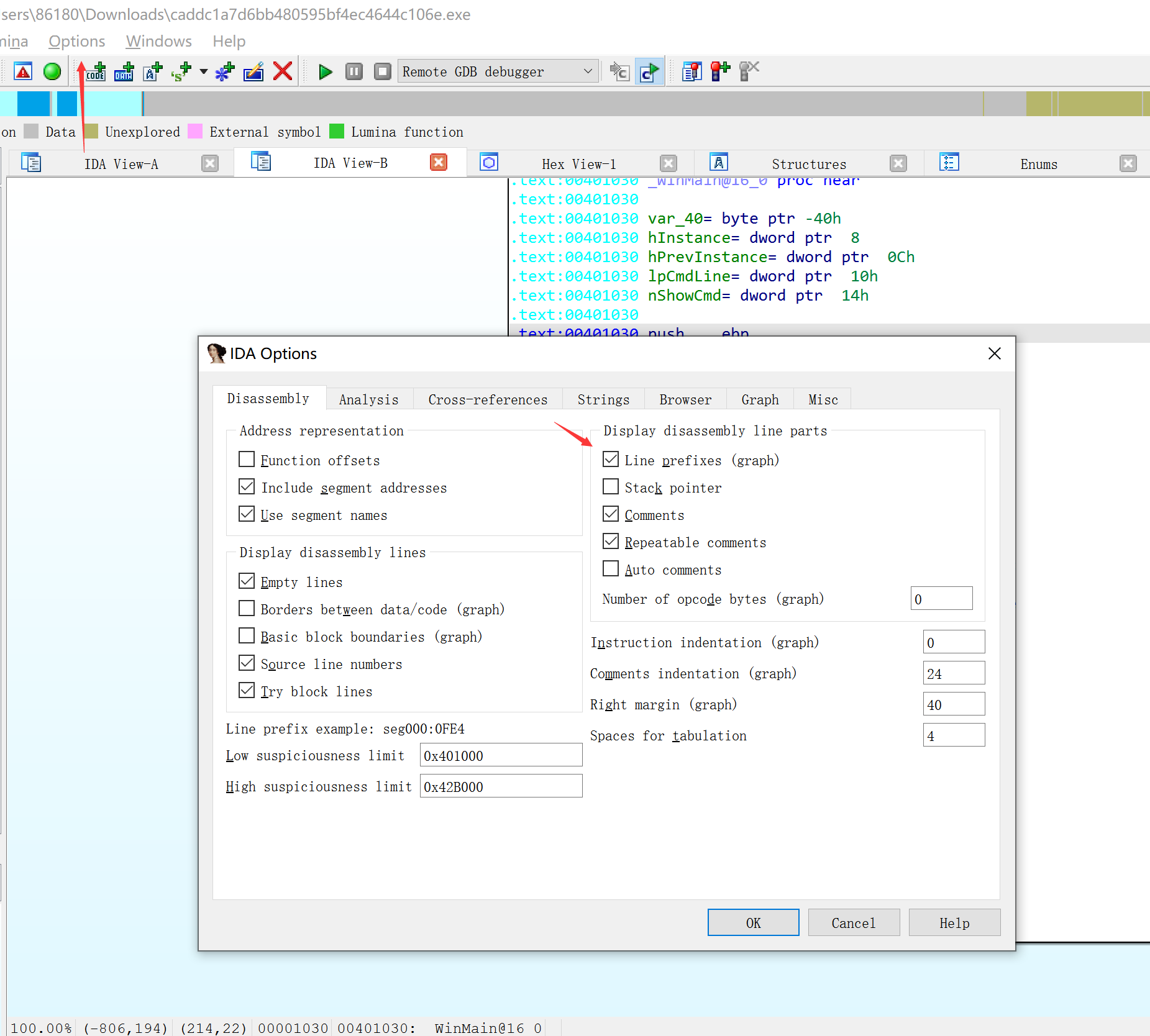
为了展示更多信息可以打开行前缀。
虚拟地址以【区域名称】:【虚拟地址】这种格式显示,如.text:0040110c0。
name窗口
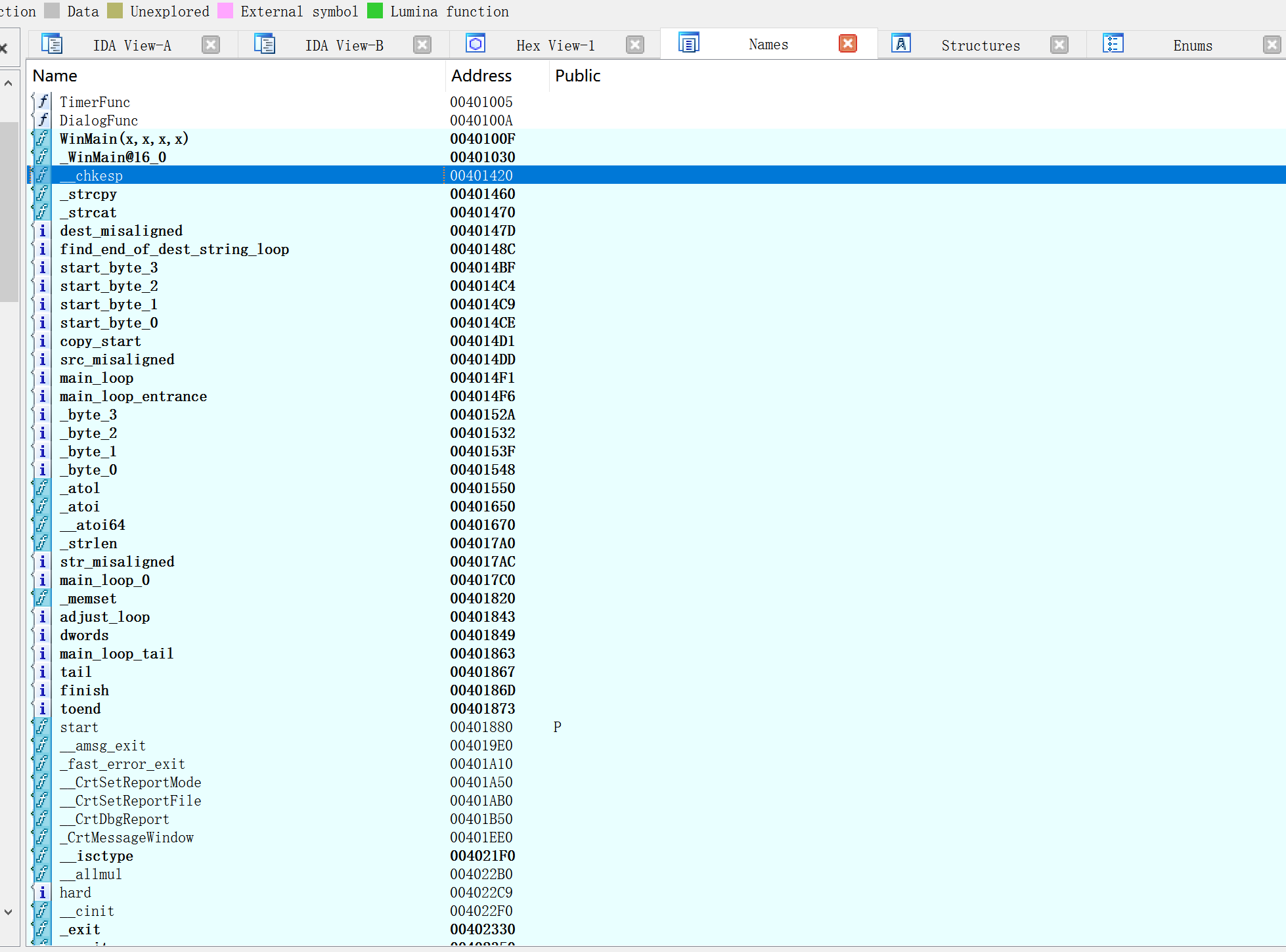
shift+f4打开,它简要列举了一个二进制文件的所有全局名称。名称是指对一个程序虚拟地址的符号描述。在最初加载文件的过程中,IDA会根据符号表和签名分析派生出名称列表。用户可通过Names窗口快速导航到程序列表中的一直位置。
消息窗口

IDA执行相关,以及脚本执行相关。
Strings窗口
Shift+f12打开
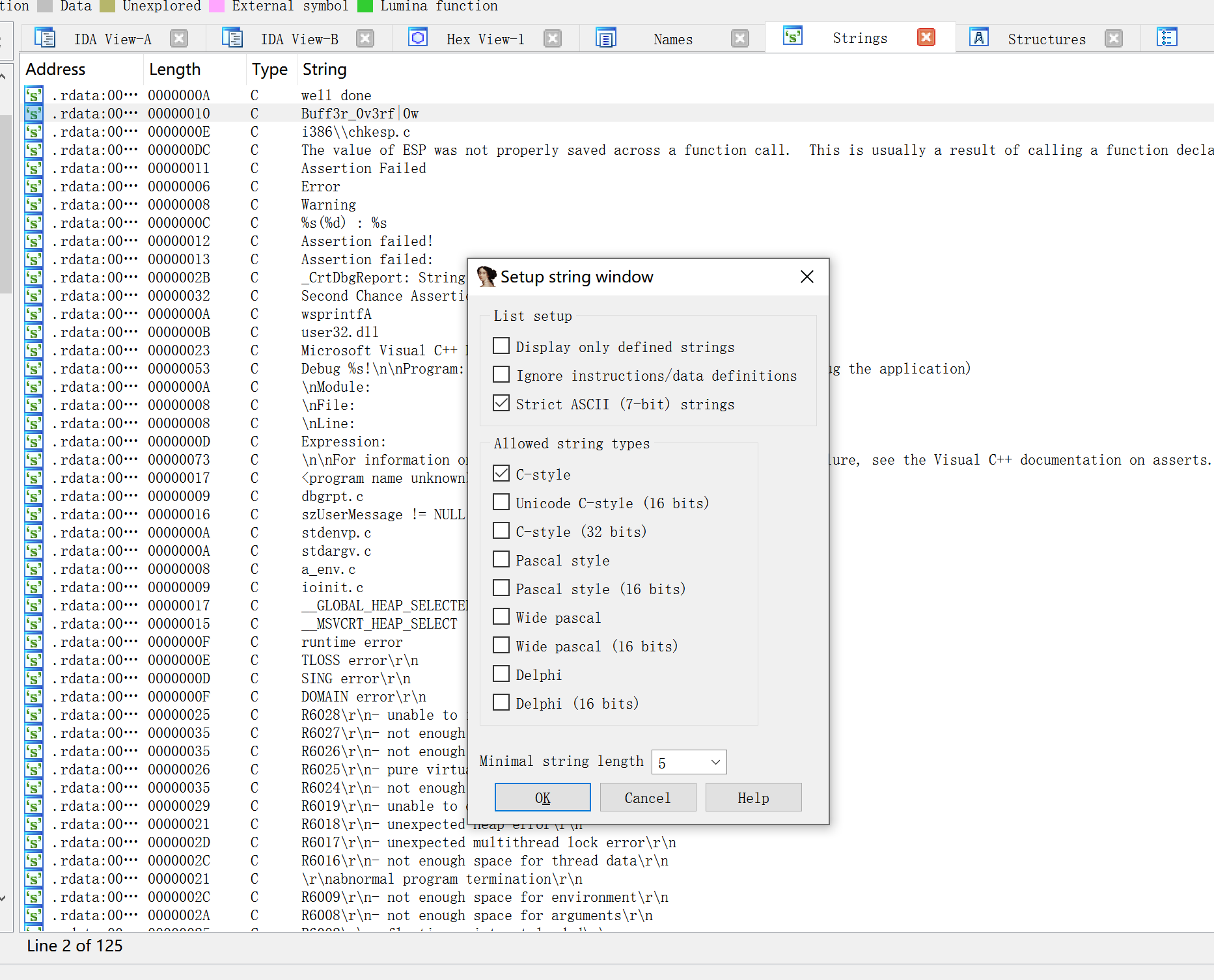
要显示C风格以外的字符串,配置setup string windows。
ignore instruction/data definitions,这个选项会是IDA扫描指令和现有数据定义中的字符串。
导出窗口
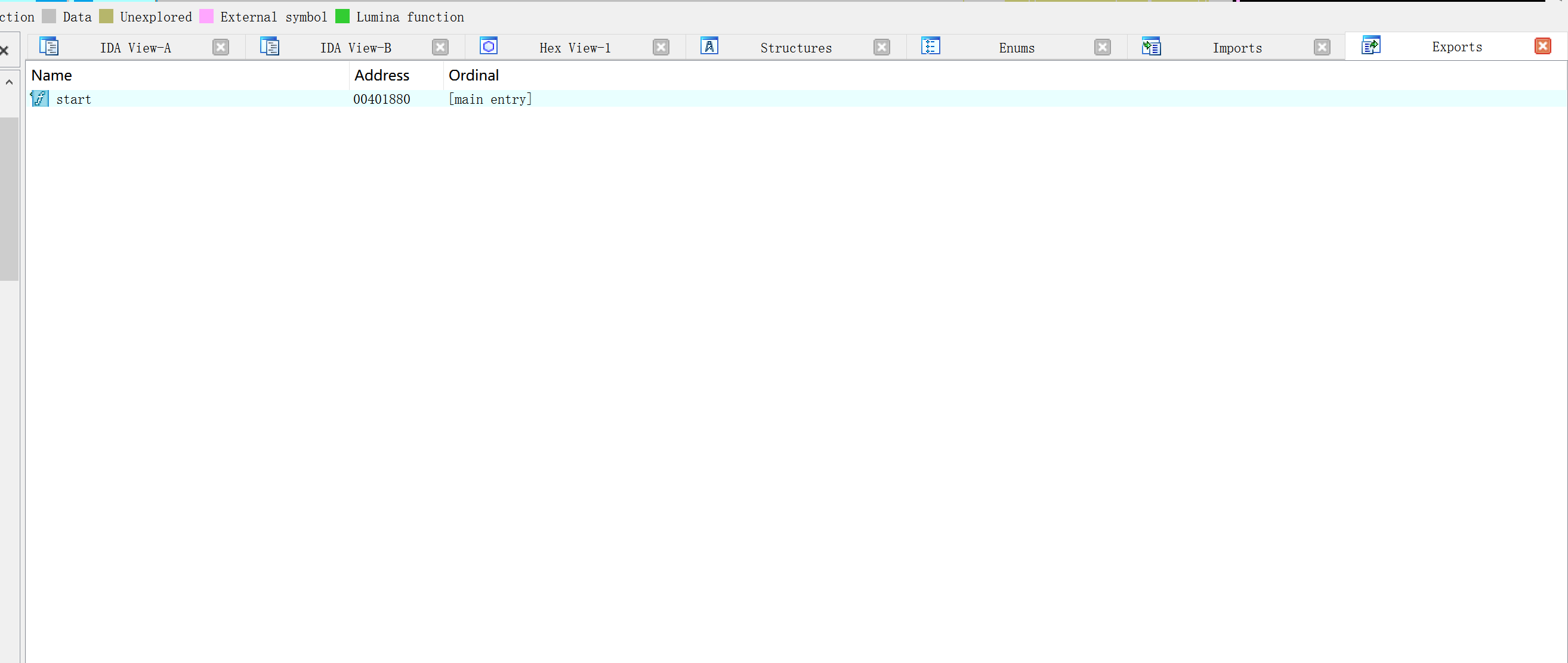
导出窗口列出文件的入口点。这包括程序的执行入口点,以及任何由文件到处给其他文件使用的变量或者函数。
导入窗口
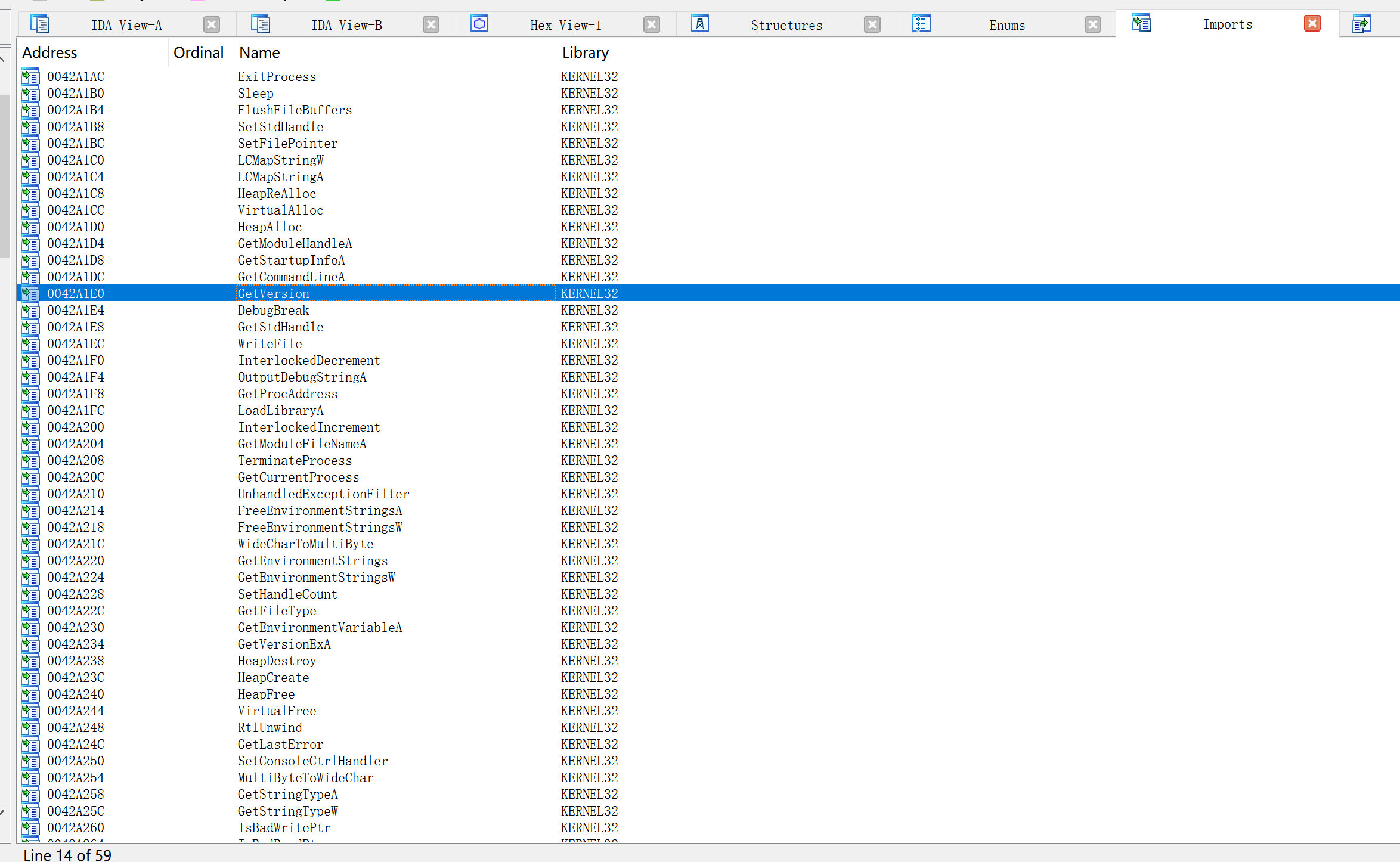
导入窗口的功能是列出由被分析二进制文件导入的所有函数。导入窗口仅显示二进制文件想要动态加载其自行处理的符号,二进制文件选择使用dlopen/dlsym或LoadLibraruy/GetProcAdddress等机制自行加载的符号不会再导入窗口显示。
函数窗口

函数窗口用于列出数据库的每一个函数。
结构体窗口
结构体窗口用于显示IDA决定在一个二进制文件中使用的任何负载的数据结构的布局。在分析阶段,IDA会查询它的函数类型签名扩展库,设法将函数的参数类型与程序使用的内存匹配起来。
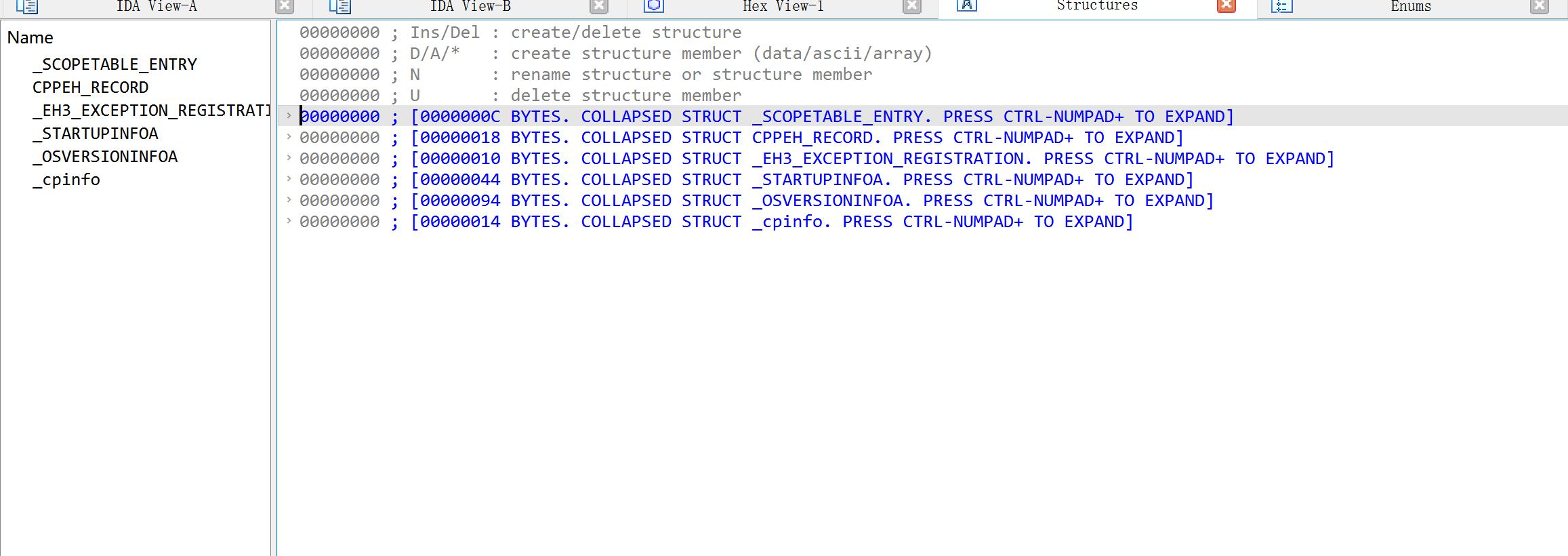
枚举窗口
IDA检测到标准枚举数据类型,它将在枚举类型传酷狗列出该数据类型。在枚举窗口中也可以定义自己的枚举类型,和应用到反汇编的代码中。
段窗口
pass
签名窗口
shift+f5打开签名窗口,IDA使用一个庞大的签名库来识别已知的代码块。签名用于识别由编译器生成的常用启动顺序,以确定可能已被用来构建给定二进制文件的编译器。签名还可以用来将函数划归为由编译器插入的已知库函数,或者因为静态链接而添加到二进制文件中的函数。
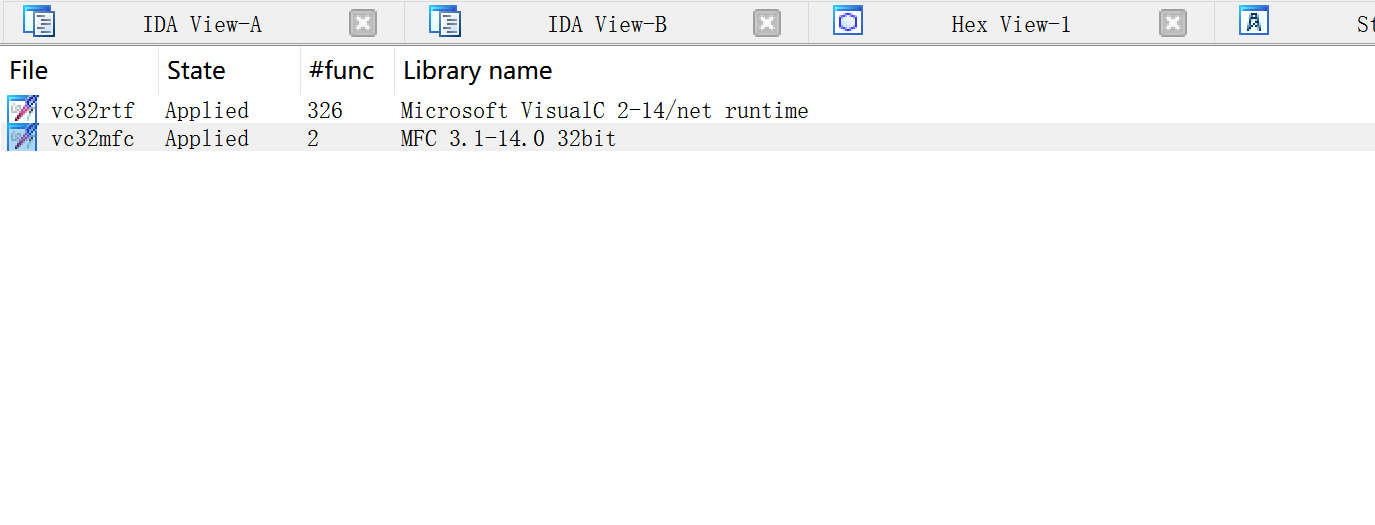
IDA已经对该二进制文件应用了vc32rtf签名,并在这个过程中将326个函数识别为库函数。
类型库窗口

类型库保存IDA积累的一些信息,即IDA从常用的编译器的头文件中搜索到的有关预定义数据类型和函数原型的信息。通过处理头文件,IDA可以确定常用库函数所需的数据类型,并为反汇编代码添加注释。
反汇编导航
反汇编一个程序,程序的每个位置都分配到了一个虚拟地址。因此,只要提供希望访问的虚拟地址,就可以导航到程序的任何地方。
跳转到地址
在反汇编窗口按下g,输入名字或者地址。esc可以跳转到前一个位置。ctrl+enter跳转到下一个位置。
调用约定
c调用约定
x86体系结构的许多c编译器使用默认的约定叫做c调用约定。c/c++程序中常用的_decl修饰符会迫使编译器利用c调用约定。调用方按从右到左的顺序将函数参数放入栈,在被调用的函数完成其操作的时候,调用方负责从栈中清除参数(本质上就是栈帧平衡)。
如果函数能够接受数量可变的参数,调用方非常适于进行这种调整,因为它清楚地知道,它向函数传递了多少个参数。
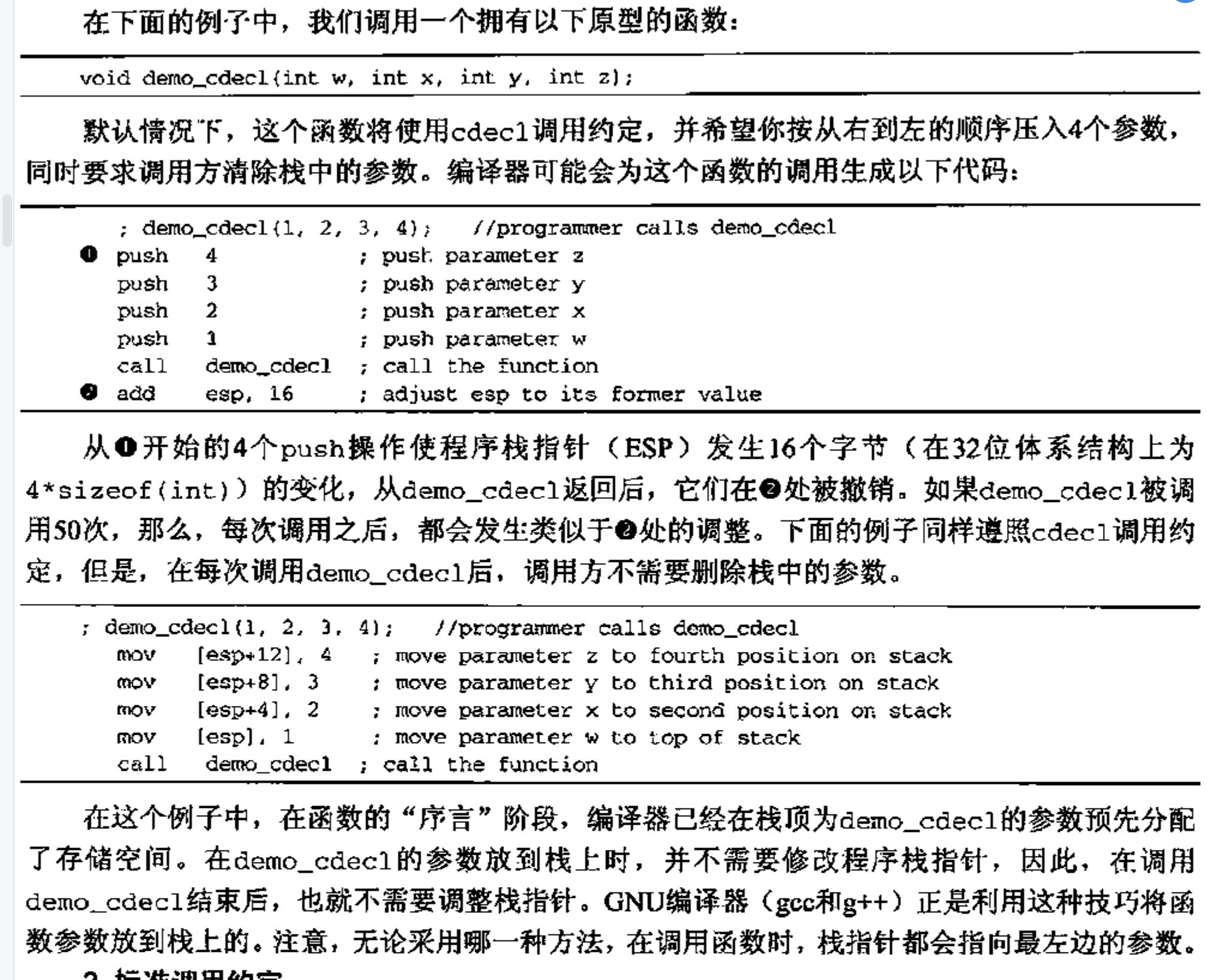
标准调用约定
微软为自己调用约定起到名称,在函数声明时使用修饰符_stdcall。它也是从右到左的顺序将函数参数放在程序栈上。函数结束执行的时候,由被调用的函数负责删除栈中的函数参数。接受可变数量的参数的函数无法使用这个调用约定。
x86编译器能使用RET指令的一种特殊形式,同时从栈顶提取返回地址,并给栈指针加上12,以消除函数参数。
ret 12 ; return and clear 12 bytes from the stack
使用stdcall的主要优点在于,在每次函数调用之后,不需要通过代码从栈中清除参数,因而能够生成体积稍小,速度稍快的程序。根据惯例,微软对所有由共享库文件输出的参数数量固定的函数使用stdcall约定。
x86 fastcall调用约定
fastcall约定是stdcall约定的一个变体,它向CPU寄存器(而非程序栈)最多传递两个参数。Microsoft Visual C/C++和GNU gcc/g++ (3.4及更低版本)编译器能够识别雨数声明中的fastcall修饰符。如果指定使用fastcall约定,则传递给函数的前两个参数将分别位于ECX和EDX寄存器中。剩余的其他参数则以类似于stdcall约定的方式从右到左放入栈上。同样与stdcall约定类似的是,在返回其调用方时,fastcall 函数负责从栈中刪除参数。下面的声明中即使用了fastcall修饰符。

局部变量布局
存在规定如何向函数传递参数的调用约定,但不存在规定函数的局部变量布局的约定。编译器的第一一个任务,是计算出函数的局部变量所需的空间。编译器的第二个任务,则是确定这些变函数的调用方无关,也与被调用的函数无关。值得注意的是,通过检查函数的源代码,通常无法函数的调用方无关,也与被调用的函数无关。值得注意的是,通过检查函数的源代码,通常无法确定函数的局部变量布局。
栈帧示例
文本搜索
在反汇编窗口进行字符串搜索alt+t,ctrl+t找到下一个搜索结果。
二进制搜索
如果需要搜索特定的二进制内容,如已知的字节序列,快捷键alt+b,ctrl+b。用引号可以搜索字符串。
反汇编操作
名称与命名
快捷键n
参数与局部变量
栈变量的名称根据给定栈帧所属的函数,这类名称的作用域受到限制。程序中的每一个函数可能都有一个名为arg_0的栈变量,但没有一个函数拥有一个以上的arg_0变量。

输入空白,IDA会生成默认的名称。
已命名的位置
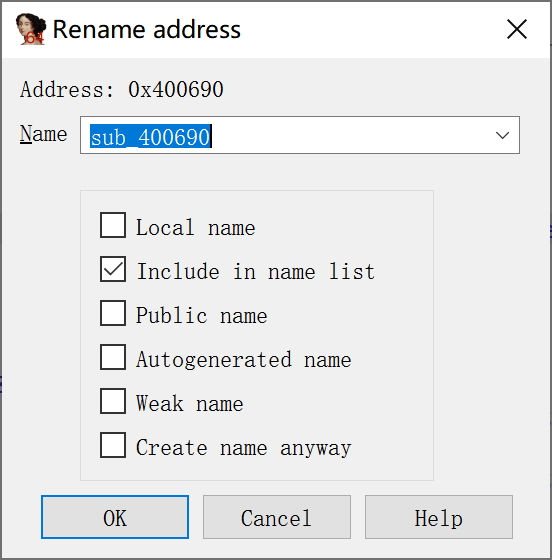
- Local names (局部名称):局部名称的作用域仅限于当前函数,因此,局部名称的唯一性仅在某个给定的函数中有效。与局部变量一样,两个不同的函数可能含有完全相同的局部名称,但一个函数不可能包含两个完全相同的局部名称。在函数边界以外的已命名的函数中的跳转目标提供符号名称,如那些与分支控制结构有关的名称。
- Include in names list (包含在名称列表中):选择这个选项将有一个名称被添加到名称窗口中,这样,当你需要返回该名称所在位置时,就更容易找到这个名称。默认情况下,自动生成的名称(哑名)不包含在名称窗口中。
- Public name (公共名称):通常,公共名称是指由二进制文件(如共享库)输出的名称。在最初加载数据库的过程中,IDA的解析器会在解析文件头的同时查找公共名称。选择这个属性,你可以迫使IDA将一个符号看成是公共名称。一般来说, 这样做除了给反汇编代码清单和名称窗口中的名称添加公共注释外,不会对反汇编代码造成任何影响。
- Autogenerated oame (自动生成的名称):这个属性似乎不会对反汇编代码产生任何明显的影响。选择它并不会使IDA自动生成一个名称。
- Weak name (弱名称):弱符号(weak symbol)是公共符号的一种特殊形式,只有没有找到相同名称的公共符号来重写时,才会使用弱符号。将一个符号标记为弱符号对汇编器有一定意义,但对IDA反汇编代码却没有任何意义。
- Create name anyway (无论如何都要创建名称):如前所述,一个函数中不会有两个位置使用相同的名称。同样,在函数以外(全局范围内),也不能有两个位置使用相同的名称。这个选项比较容易引起混淆,因为你创建的名称的类型不同,它的行为也不一样。
寄存器名称
在函数边界内,IDA允许对寄存器进行重命名。并使用它在当前函数执行期间引用该寄存器。如果一段代码不属于某个函数,重命名这段代码中的寄存器是不可能的。
IDA中的注释
常规注释
:默认情况下,常规注释以蓝色显示
可重复注释
;可重复注释一旦输入,将会自动出现在反汇编窗口的许多位置。默认颜色为蓝色。可重复注释的行为与交叉引用的概念相关。如果一个程序位置引用了另一个包含重复注释的位置,则该注释会在第一个位置回显(回显的是灰色)。
在前注释和在后注释
在前注释和在后注释是出现在指定的反汇编行之前或之后的注释,他们仅仅是不以分号为前缀的注释
函数注释
pass
基本代码转换
许多时候,对于IDA生成的反汇编代码清单,你会感到非常满意。但有些情况并非始终如此。如果你所分析的文件类型与常见编译器生成的曾通二进制可执行文件相差甚大,你可能需要对反汇编分析和显示过程进行更多的控制。在分析采用自定义文件格式(IDA无法识别)的模糊代码或文件时,情况更是如此。
IDA提供的代码转换包括以下几类。
- 将数据转换为代码;
- 将代码转换为数据;
- 指定一个指令序列为函数;
- 更改现有函数的起始或结束地址;
- 更改指令操作数的显示格式。
利用这些操作的频繁程度取决于诸多因素及你的个人喜好。一般而言, 如果二进制文件非常复杂,或者说IDA不熟悉用于构建二进制文件的编译器所生成的代码序列,那么,IDA在分析阶段可能会遇到更多麻烦;因此,你也就需要对反汇编代码进行手动调整。
格式化指令操作数
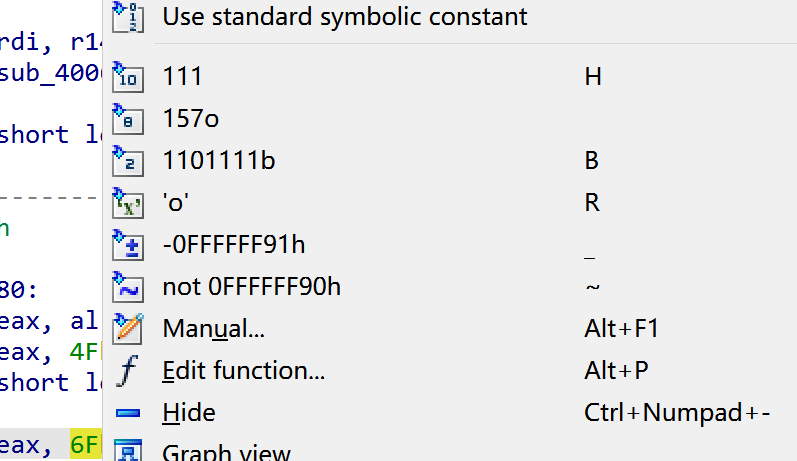
use stander symbolic constant可以选择将操作数替换成一些标准库中的枚举常量。
操作函数
IDA无法定位一个函数调用,由于无法到达函数,IDA将无法识别它们。IDA也可能无法确定函数的结束部分,需要手动干预。编译器优化代码将数个函数的指共同指结束序列合并在一起,IDA也无法确定函数的结束部分。
新建函数
将光标放在新函数的第一个字节或指令上,选择edit->function->creat function即可以创建一个新函数。必要的时候IDA会把数据转换成代码。接下来,它向前扫描,分析函数的结构,并搜索放回语句。如果找到函数的结束部分就创建一个新的函数名,分析栈帧。无法找到结束部分或者找到非法指令,操作失败。
删除函数
edit->function->delete function
函数块
vc++编译器生成的代码,经常可以找到函数块。编译器移动不常执行的代码段,用以将经常执行的代码段“挤入”不太可能换出的内存也,由此便产生了函数块。
如果一个函数以这种方式被分割,ida会通过跟踪指向每个块的跳转,尝试定位所有相关的块。
函数属性
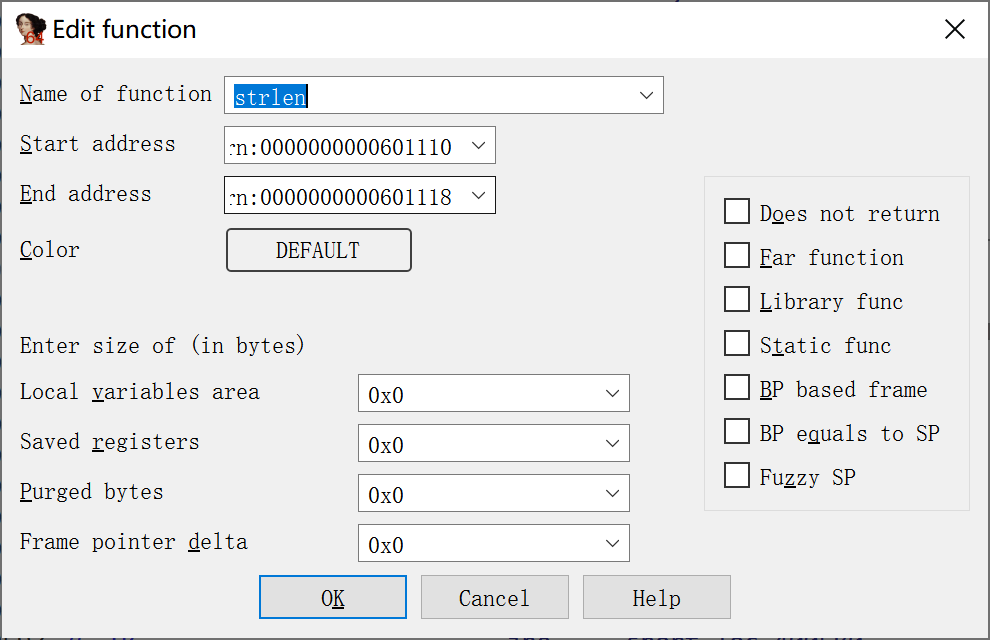
- 函数名称
- 起始地址
- 结束地址 函数最后一条指令之后的地址
- 局部变量区 局部变量专用的栈字节数
- 保存到寄存器 保存寄存器所使用的字节数
- 已删除字节 表示当函数返回调用方的时候,IDA从栈中删除的参数的字节数。对cdecl函数而言,这个值为0;对stdcall函数而言,这个值表示传递到栈上所有参数占用的空间。在x86程序中,如果IDA观察到程序使用了返回指令的RETN变体,他将自动确定这个值。
- 帧指针增量 有时候,编译器可能会对函数的帧指针进行调整,使其指向局部变量区域的中间,而不是指向保存在局部变量区域底部的帧指针。调整后的帧指针到保存的帧指针之间的这段距离叫做帧指针增量(frame pointer delta)。多数情况下,IDA会在分析函数的过程中自动计算出帧指针增量。编译器利用栈帧增量进行速度优化。使用增量的目的,是在离帧指针1个字节(带符号)的偏移量(-128+127) 内保存尽可能多的栈帧变量。
- 不返回 函数不返回到它的调用方,如果调用这样的函数。在相关的调用指令之后,IDA认为函数不会继续执行。
- 远函数 这个属性用与在分段体系结构上将一个函数标记为远函数。
- 库函数 将一个函数标记为库函数
- 静态函数 除在函数的属性列表中显示静态修饰符外,其他扫描也不做
- 基于bp的帧 这个属性表示函数利用了一个帧指针。
- bp=sp 它的作用等同于将帧指针增量的大小设置为等于局部变量区域。
数据与代码互相转化
反汇编界面u转为数据 c转为代码
基本数据转换
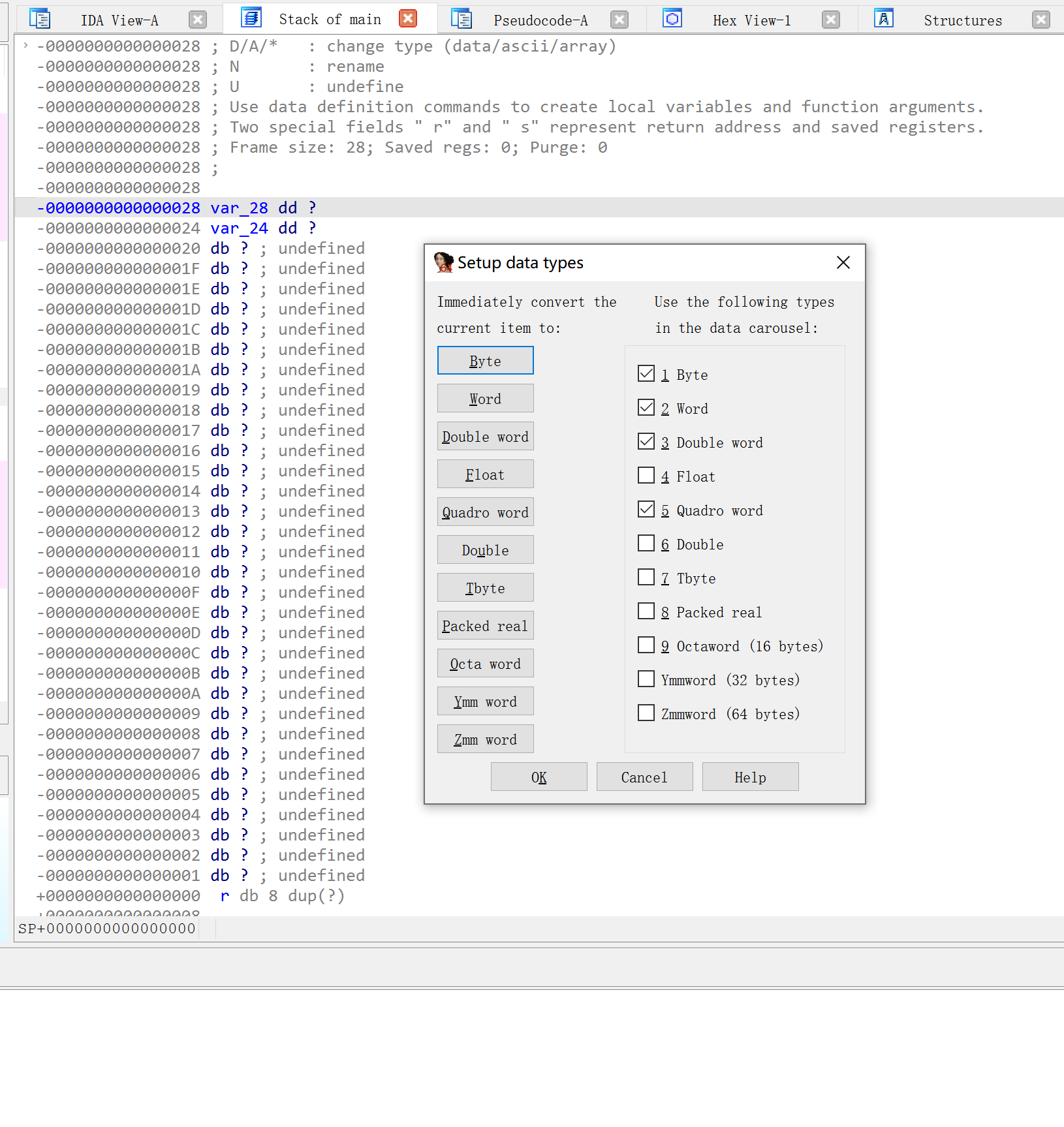
alt+d指定数据大小
此上是第七章及之前的内容

文章评论